

The notebook works. The eval looks clean. You ship. Two weeks later a customer screenshots an answer your model has no business giving, and you cannot reproduce it. No trace. No version history on the prompt that changed last Tuesday. No score on what "good" even meant for that request.
This is the gap LLMOps fills. Where MLOps managed deterministic models with clear accuracy metrics, llm operations deal with non-determinism, fragile prompts, multi-step agent workflows, and outputs that resist simple pass/fail grading. The operational layer that handles evaluation, llm tracing, prompt management, production monitoring, and governance is no longer optional once your app touches real users.
The money agrees. The MLOps market, a close proxy for LLMOps infrastructure, is projected to grow from $4.39B in 2026 to $89.91B by 2034 at a 45.8% CAGR, according to Fortune Business Insights (2024). And Index.dev (2026) reports that over 80% of enterprises are expected to deploy generative AI apps or APIs by 2026. The tooling that keeps those apps reliable is now a budget line, not a side project.
The trouble is that "what is llmops" gets answered differently by every vendor. Some tools own evaluation. Some own observability. Some own the AI gateway. Picking an llmops platform means understanding which layer of the stack each tool actually owns. If you are also evaluating adjacent infrastructure, our roundups on AI governance tools, application performance monitoring tools, and AI security posture management tools pair well with the decisions below.
What's inside
This guide ranks 10 llmops tools that own a clear part of the stack, not generic AI platforms that bolt on a logging tab. It is written for ML engineers, MLOps engineers, AI platform leads, and product engineering teams shipping LLM apps into production.
We selected tools based on four criteria:
- Evaluation depth: offline evals, regression tests, LLM-as-a-judge, and human review.
- Observability and tracing: span-level traces, token cost attribution, and agent-step visibility.
- Governance and cost controls: access control, routing, auditability, and budget guardrails.
- Production readiness: deployment model, framework compatibility, and integration scope.
Pricing and G2 ratings reflect values verified at the time of writing. Check vendor pages before you commit budget.
TL;DR
- Best for evaluation-first teams: Braintrust turns production logs into tests so iteration is driven by data, not vibes.
- Best for teams already on product analytics: PostHog folds LLM tracing into the same platform running your analytics, session replay, and feature flags.
- Best for packaged evaluators and guardrails: Galileo AI ships productized scoring and runtime guardrails for teams that want evaluation operationalized.
- Best for ML teams extending into LLMs: Weights & Biases bridges experiment tracking into LLM tracing and evals through Weave.
- Best for infrastructure-first teams: TrueFoundry centers on an AI gateway, serving, and routing for governed deployment.
- Best for open-source-first teams: MLflow, Langfuse, and LiteLLM give you self-hostable tracing, evaluation, prompt management, and gateway control.
What is LLMOps?
LLMOps is the operational layer for building, evaluating, deploying, monitoring, and continuously improving applications built on large language models.
The lifecycle runs in a loop: prompt engineering, llm evaluation, deployment, production monitoring, and continuous improvement fed back into the next prompt iteration. Each stage produces signal the next stage needs. Traces from production become the test cases for your next eval. Eval failures point to the prompt that needs a new version. Monitoring catches the regression an offline test missed.
LLMOps differs from MLOps in three ways that matter operationally:
- Non-determinism. The same input can produce different outputs across runs, so a single golden answer is rarely enough. You grade ranges of acceptable behavior, not exact matches.
- Prompt fragility. A one-word change to a system prompt can shift behavior across thousands of requests. Prompt versioning and rollback become first-class concerns, not afterthoughts.
- Evaluation difficulty. Quality is often subjective, which is why LLM-as-a-judge models and human review sit at the center of the workflow rather than a fixed accuracy number.
The core capability buckets a serious llmops platform covers:
- Evaluation and regression testing
- Observability, tracing, and semantic debugging
- Prompt management, versioning, and rollback
- Governance, access control, and cost attribution
- Deployment, routing, and runtime guardrails
What to look for in LLMOps tools
The category is crowded, and most marketing pages blur together. These four areas separate tools that hold up in production from tools that look good in a demo.
Evaluation and test coverage
Evaluation is where LLMOps either earns its keep or becomes theater. Good evaluation means offline eval suites you run before every deploy, regression tests that catch when a prompt change breaks an old behavior, judge models that score subjective quality at scale, and human review for the cases judges get wrong.
What to verify: can you build datasets from real production traffic, not just synthetic examples? Can you run the same eval offline and online? Does the tool support LLM-as-a-judge scoring alongside code-based assertions? Evaluation-first development means the eval suite is the source of truth, and every prompt or model change is measured against it before it ships.
Observability and debugging depth
When an agent gives a wrong answer three steps deep, you need to see every step. That means traces and spans for each model call, token cost attribution per request and per workflow, prompt lineage so you know which version produced which output, and agent-step visibility across tool calls and retries.
The test here is production debugging, not vanity dashboards. A chart showing average latency is nice. A trace that lets you replay the exact sequence of calls behind a single bad response is what actually shortens your time to fix. Look for trace intelligence that surfaces the failing span, not just aggregate numbers.
Governance, safety, and cost controls
Once multiple teams share model infrastructure, governance and safety stop being optional. Look for role-based access control, audit logs, policy enforcement on what models and prompts can do, routing that sends requests to the right provider, and budget guardrails that cap spend before a runaway loop drains your account.
Security and compliance expectations matter here too: SSO, data retention controls, and the ability to keep sensitive data out of logs. If you operate in a regulated environment, an AI gateway with runtime guardrails and centralized policy is often the difference between shipping and waiting on a security review. Our guide to audit management software is a useful companion when compliance is in scope.
Production readiness and stack fit
A tool that owns one perfect layer is useless if it does not fit your stack. Evaluate deployment model (managed, self-hosted, or both), latency overhead the tracing adds, framework compatibility with your orchestration layer, and the depth of integrations into your existing observability and data tooling.
| Production-readiness check | What to verify |
|---|---|
| Deployment model | Managed cloud, self-host, or hybrid |
| Latency overhead | Async tracing that does not block requests |
| Framework fit | Works with your orchestration and SDKs |
| Standards | OpenTelemetry-compatible tracing |
| Integrations | Connects to your data and alerting stack |
When to use LLMOps tools
Not every project needs a full LLMOps stack on day one. These three triggers tell you when ad hoc tooling stops being enough.
Ship LLM apps beyond prototypes
The moment your LLM feature leaves the demo and touches real users, notebooks and copy-pasted prompts stop scaling. You need a record of what shipped, a way to measure quality before each release, and alerts when production behavior drifts. That is the trigger to adopt an llmops platform rather than wiring together logging by hand.
Debug prompts and agent workflows
When failures are easy to reproduce, you can debug by hand. When an agent fails intermittently across a five-step workflow, you cannot. Tracing and evaluation become mandatory the moment you cannot answer "why did it do that?" by reading the code. Semantic debugging across spans is what lets you find the one retrieval step that returned garbage.
Govern usage across teams and environments
Once two or more teams or business units share the same model infrastructure, centralized controls matter. You need to attribute token cost by team, enforce policy on which models each group can call, and cap budgets per environment. This is when an AI gateway and centralized governance move from nice-to-have to required.
Comparison table
The table below is organized by stack role, not alphabetically. Evaluation-first and observability tools lead, followed by infrastructure and gateway tools, so you can scan to the layer you are buying for.
| # | Product | Intent | Key differentiation | Pricing | G2 rating |
|---|---|---|---|---|---|
| 1 | Braintrust | Evaluation-first LLMOps | Turns production logs into tests with scoring and alerts | Free; Pro $249/mo; Enterprise custom | 4.4/5 |
| 2 | PostHog | Observability plus analytics | LLM tracing inside a full product analytics platform | Usage-based from $0.00005/event; free tier | 4.5/5 |
| 3 | Galileo AI | Evaluation and guardrails | Packaged evaluators with real-time protection | Free; Pro from $100/mo; Enterprise custom | 4.4/5 |
| 4 | Weights & Biases | Experiment tracking to LLM | Weave extends ML tracking into LLM evals and traces | Personal free; Starter from $50/user/mo | 4.7/5 |
| 5 | TrueFoundry | Infrastructure-first LLMOps | AI gateway, serving, routing, and governance | Developer free; Pro $499/mo; Pro Plus $2999/mo | 4.6/5 |
| 6 | MLflow | Open-source LLMOps | Tracing, prompt registry, evals, and AI gateway, open source | Free and open source | - |
| 7 | LangSmith | Agent observability and evals | Tracing, evals, and deployment for agent workflows | Developer free; Plus $39/seat/mo; Enterprise custom | 4.7/5 |
| 8 | Langfuse | Open observability and evals | Self-host or managed tracing, evals, and prompt management | Hobby free; Core $29/mo; Pro $199/mo | - |
| 9 | PromptLayer | Prompt management | Prompt registry, versioning, and cost intelligence | Free tier available | 4.5/5 |
| 10 | LiteLLM | AI gateway and routing | OpenAI-compatible gateway across many providers | Open source free; Enterprise on request | - |
1. Braintrust
Braintrust is an AI observability and evaluation platform built around evaluation-first development. It traces every AI call in production, scores live traffic with evals and alerts, and uses its Loop agent to iterate on prompts, scorers, and datasets in one place. The core idea is simple and powerful: production logs become test cases, so your evals improve as your traffic grows.
That loop is what separates Braintrust from tools that treat evaluation as a one-time gate. Instead of writing synthetic test cases and hoping they cover reality, you pull real failing traces into a dataset, score them, and run every future prompt change against that growing suite. It supports llm evaluation through code-based scorers and judge models, and it keeps the whole team working from the same datasets and scores.
Best for: teams shipping AI products that want observability and evaluation in one platform with a tight production-to-test feedback loop.
Key strengths
- Production-to-test loop: Turn live traces into evaluation datasets so tests reflect real traffic, not guesses.
- Live scoring and alerts: Score production traffic continuously and get alerted when quality drifts.
- Loop iteration agent: Iterate on prompts, scorers, and datasets without leaving the platform.
Why choose Braintrust: If your team treats evaluation as the source of truth and wants every prompt change measured before it ships, Braintrust is built for exactly that motion. It fits engineering teams that already log heavily and want those logs to do double duty as a test suite.
Braintrust pricing: The Starter plan is free and includes $10 in credits, 1 GB of processed data, 10k scores, and 14-day retention. Pro is $249/month with $249 in credits, 5 GB processed, 50k scores, and 30-day retention. Enterprise is custom pricing. Braintrust holds a 4.4/5 rating on G2.
2. PostHog
PostHog is an all-in-one product OS that combines product analytics, web analytics, session replay, error tracking, feature flags, experiments, and a data warehouse. For LLM apps, that means you can layer tracing and cost visibility on top of the same platform that already tracks how users move through your product, then tie model behavior to actual user outcomes.
The advantage is consolidation. If your team already runs analytics, feature flags, and experiments in PostHog, adding observability for llm apps avoids spinning up a separate tool and stitching two data models together. You can flag a new model version, run an experiment, watch session replays of users hitting that feature, and attribute cost in one place.
Best for: product teams that want integrated, usage-based analytics and feature management alongside LLM observability.
Key strengths
- Unified analytics and observability: Connect LLM traces to product analytics and session replay in one platform.
- Feature flags and experiments: Roll out and test model versions with the same flagging system you use for product features.
- Usage-based pricing: Pay per event, recording, or request, with generous free tiers.
Why choose PostHog: PostHog fits teams that value one platform over a best-of-breed sprawl. When your analytics and your LLM observability share a data model, debugging why a feature underperforms gets faster because the product context is already there.
PostHog pricing: Pricing is usage-based with generous monthly free tiers. Product analytics runs $0.00005 per event, session replay $0.005 per recording, feature flags $0.0001 per request, and managed warehouse $0.000015 per row. PostHog notes that 98% of customers use it for free. It holds a 4.5/5 rating on G2.
3. Galileo AI
Galileo AI is an evaluation, observability, and real-time protection platform for teams shipping AI apps with confidence. It packages evaluators, inline scoring, and runtime guardrails so evaluation moves from a research exercise into an operational control. Rather than building judge logic from scratch, you get productized evaluators you can apply to traces and live traffic.
The runtime protection piece is where Galileo leans hardest. Guardrails inspect outputs as they happen and can block or flag responses that violate policy, which matters for governance and safety in regulated or high-stakes deployments. Combined with observability and packaged evals, it gives teams operationalized evaluation rather than a pile of metrics to interpret.
Best for: teams building and monitoring AI applications that need evaluation, observability, and guardrails in a single packaged platform.
Key strengths
- Packaged evaluators: Apply ready-made scoring to traces and live traffic without writing judges from scratch.
- Real-time protection: Inspect and guard outputs at runtime to enforce policy before responses reach users.
- Observability with inline scoring: Trace behavior and score it in the same view for faster debugging.
Why choose Galileo AI: Galileo suits teams that want evaluation operationalized and paired with runtime guardrails, especially in enterprise contexts where output safety is non-negotiable. It is a strong fit when you need scoring and protection working together, not as separate systems.
Galileo AI pricing: The Free plan is $0/month and includes 5,000 traces per month, unlimited users, and unlimited custom evals. Pro starts at $100/month billed yearly, adding 50,000 traces per month, RBAC, analytics, and Slack support. Enterprise is custom with unlimited scale and deployment options. Galileo holds a 4.4/5 rating on G2.
4. Weights & Biases
Weights & Biases is an AI developer platform known for experiment tracking, model management, and model lineage. Through Weave, its LLM-focused toolkit, it extends that foundation into LLM application evaluation, tracing, and monitoring, making it a natural bridge for ML teams moving from classic model training into LLM apps.
If your team already lives in W&B for experiment tracking, the jump to LLM workflows keeps your data, collaboration, and history in one place. Weave adds llm tracing and eval workflows on top of the metrics, hyperparameters, and artifacts you already log. That continuity is the pitch: you do not abandon your ML tooling to start doing LLMOps.
Best for: ML teams that want centralized experiment tracking and collaboration, then extend the same platform into LLM evaluation.
Key strengths
- Experiment tracking: Log metrics, hyperparameters, and artifacts with full history and comparison.
- Model registry and lineage: Track model versions and provenance across the lifecycle.
- Weave for LLM apps: Add tracing, evaluation, and monitoring for LLM workflows on the same platform.
Why choose Weights & Biases: W&B is the right call when you already run ML experiments on it and want LLM evaluation without adopting a second system. The bridge from experimentation to LLM apps keeps collaboration and data lineage intact across both motions.
Weights & Biases pricing: The Personal plan is free for one user. Starter begins at $50.00 per user per month, and Enterprise is contact-us pricing. W&B holds a 4.7/5 rating on G2.
5. TrueFoundry
TrueFoundry is an AI platform for building, deploying, and governing agentic AI and ML workloads, built around an AI gateway. The gateway handles routing, observability, and governance, while MCP gateway and agentic deployment support cover the runtime side. RBAC, SSO, and enterprise compliance controls round out the governance story.
This is infrastructure-first LLMOps. Where evaluation tools focus on quality, TrueFoundry focuses on deployment and runtime control: routing requests across providers, enforcing policy at the gateway, and keeping observability and governance centralized as you scale. For platform teams responsible for how LLMs are served and governed across an organization, that emphasis fits the job.
Best for: teams building and operating governed AI applications at scale who need gateway, serving, and routing in one platform.
Key strengths
- AI gateway: Route, observe, and govern LLM traffic through a single control point.
- Agentic deployment: Deploy agents and MCP-based workflows with runtime support.
- Enterprise governance: Enforce RBAC, SSO, and compliance controls across teams.
Why choose TrueFoundry: TrueFoundry is the fit when your priority is production readiness and runtime control rather than evaluation tooling. Platform teams that need to serve, route, and govern model traffic centrally get an infrastructure layer purpose-built for that mandate.
TrueFoundry pricing: The Developer plan is free. Pro is $499/month, Pro Plus is $2999/month, and Enterprise is custom, with additional usage charges noted on some plans. TrueFoundry holds a 4.6/5 rating on G2.
6. MLflow
MLflow is the open-source AI engineering platform that grew well beyond classic experiment tracking. Today it spans LLM and agent tracing, evaluation with built-in metrics and LLM judges, a prompt registry with prompt optimization, monitoring, and AI gateway capabilities. It is fully open source and self-hostable, which makes it a default starting point for teams that want to own their stack.
The breadth is the story. Rather than buying separate tools for tracing, prompt management, and evaluation, MLflow consolidates them under one open project with OpenTelemetry-compatible thinking baked in. For teams with the engineering bandwidth to run their own infrastructure, that consolidation and control is hard to beat.
Best for: teams that want self-hosted, open-source MLOps and LLMOps tooling spanning tracing, evaluation, and prompt management.
Key strengths
- LLM and agent tracing: Capture span-level traces for LLM calls and agent workflows.
- Evaluation with LLM judges: Score quality with built-in metrics and judge models.
- Prompt registry: Version, optimize, and manage prompts alongside tracing and evals.
Why choose MLflow: MLflow is the open-source default for teams that want to own deployment and avoid vendor lock-in. When you have the engineering capacity to self-host and want tracing, evaluation, and prompt management under one roof, it covers the full lifecycle.
MLflow pricing: MLflow is open source and 100% free, with no public paid pricing tier on the project site. Hosting and infrastructure costs depend on how you run it. As an open-source project, it does not carry a standard G2 product rating.
7. LangSmith
LangSmith is an agent engineering platform from LangChain for observing, evaluating, and deploying AI agents. It offers tracing with dashboards and alerts, evaluation with LLM-as-a-judge, code-based, and multi-turn evaluators, and a durable runtime with versioning and rollback for deployment. For teams building on the LangChain ecosystem, the integration is tight and natural.
The agent angle is where LangSmith earns its place. Debugging multi-turn agent workflows requires trace-level visibility into every tool call and decision, and LangSmith was designed around that need. Its multi-turn evaluators and durable runtime make it well suited to teams whose apps are agents, not just single-shot completions.
Best for: teams building and operating production LLM agents that need tracing, evals, and managed deployment.
Key strengths
- Agent tracing: Inspect every step, tool call, and retry across multi-turn agent workflows.
- Flexible evaluators: Score with LLM-as-a-judge, code-based, and multi-turn evaluators.
- Deployment with rollback: Ship agents on a durable runtime with versioning and rollback.
Why choose LangSmith: LangSmith is the obvious fit if your stack is built on LangChain and your apps are agentic. The combination of deep tracing, agent-aware evaluation, and managed deployment covers the full loop for agent builders.
LangSmith pricing: The Developer plan is free for one seat with pay-as-you-go usage. Plus is $39 per seat per month with usage-based charges, and Enterprise is custom pricing. LangChain holds a 4.7/5 rating on G2 across its product line.
8. Langfuse
Langfuse is an open-source AI engineering platform for tracing, evaluating, and improving LLM applications. It covers observability and application tracing, evaluation with scores, datasets, experiments, and annotation, plus prompt management, metrics, and dashboards. The open infrastructure and self-host option make it popular with engineering teams that want control.
Langfuse hits a sweet spot between open-source flexibility and a polished managed offering. You can self-host for full data control or run the managed version to skip infrastructure work, and the feature set covers the three pillars most teams need: traces, evals, and prompt management. That combination of developer control and breadth is why it shows up so often in production stacks.
Best for: teams building production LLM apps that need observability, evaluation, and prompt iteration with open infrastructure.
Key strengths
- Application tracing: Capture detailed traces and spans across LLM and agent workflows.
- Evaluation suite: Run scores, datasets, experiments, and human annotation in one place.
- Prompt management: Version and manage prompts alongside metrics and dashboards.
Why choose Langfuse: Langfuse suits teams that want open infrastructure and developer control without giving up evaluation and prompt management depth. The choice between self-hosting and managed deployment lets you match it to your data and infrastructure needs.
Langfuse pricing: Hobby is free. Core starts at $29/month, Pro at $199/month, and Enterprise at $2499/month, with a Teams add-on listed at $300/month. Self-hosting the open-source version is available for teams that prefer to run their own infrastructure.
9. PromptLayer
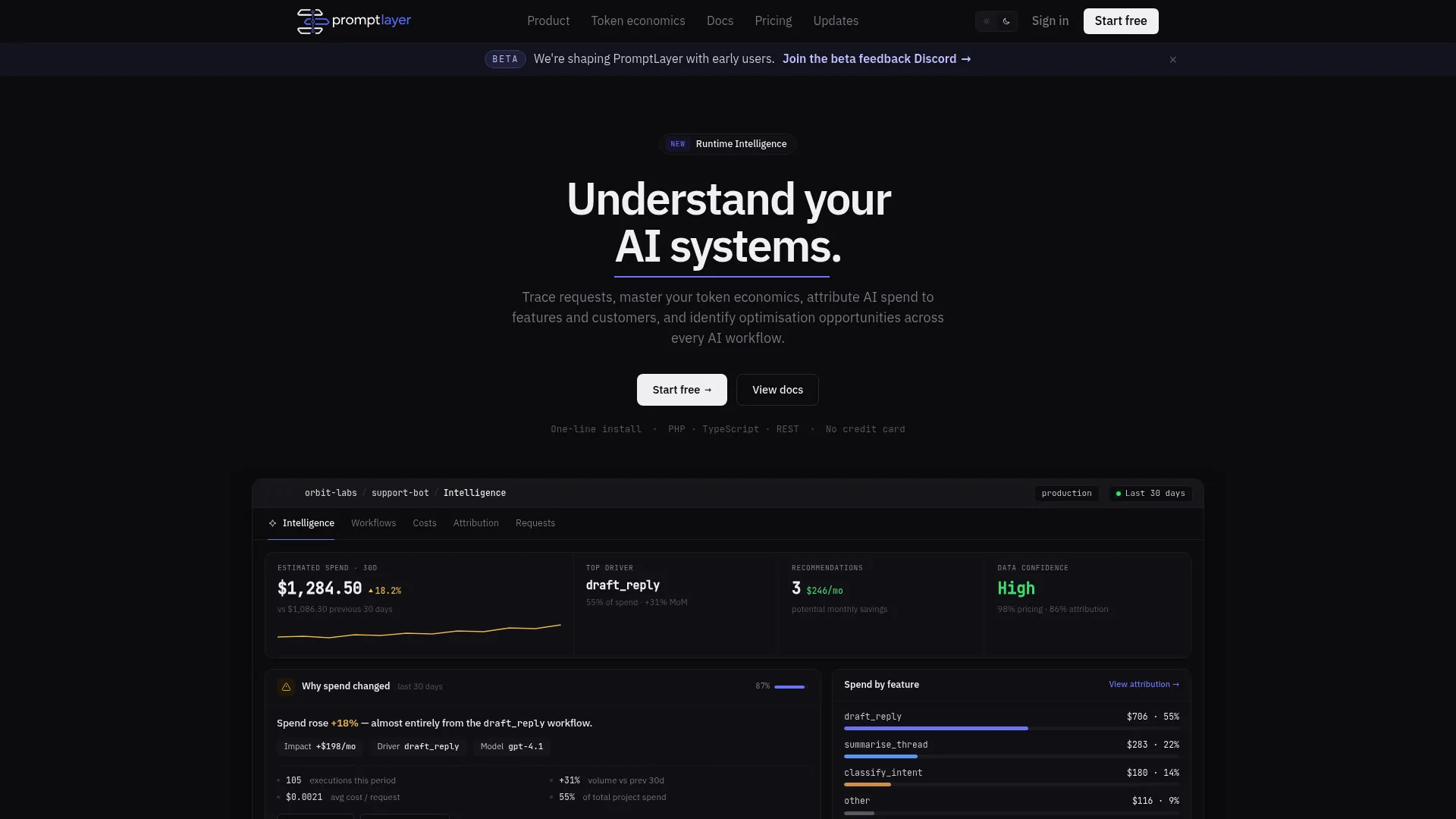
PromptLayer is an AI observability and cost-intelligence platform centered on tracing, debugging, and understanding LLM workflows, with prompt management as its main angle. It pairs runtime intelligence and workflow visibility with cost intelligence, so teams that want tighter control over prompt iteration get a registry and tracking built for that purpose.
Prompt lifecycle management is the throughline. PromptLayer makes prompts a managed artifact: you version them, log how each version performs, and attribute token cost back to specific prompts and workflows. For teams where the prompt is the product and iteration speed matters, that focus on prompt versioning and spend attribution is the draw.
Best for: teams building LLM apps that want tracing, observability, and spend attribution centered on prompt management.
Key strengths
- Runtime intelligence: Trace and debug LLM workflows as they run in production.
- Workflow visibility: See how prompts and chains behave across multi-step flows.
- Cost intelligence: Attribute token spend to specific prompts and workflows.
Why choose PromptLayer: PromptLayer fits teams that treat prompt management as the center of their workflow and want versioning, logging, and cost attribution in one tool. When prompt iteration speed is your bottleneck, that focus pays off.
PromptLayer pricing: PromptLayer offers a free start with no credit card required. The team has not published numeric tier pricing on its site, so check current plans directly before committing. It holds a 4.5/5 rating on G2.
10. LiteLLM
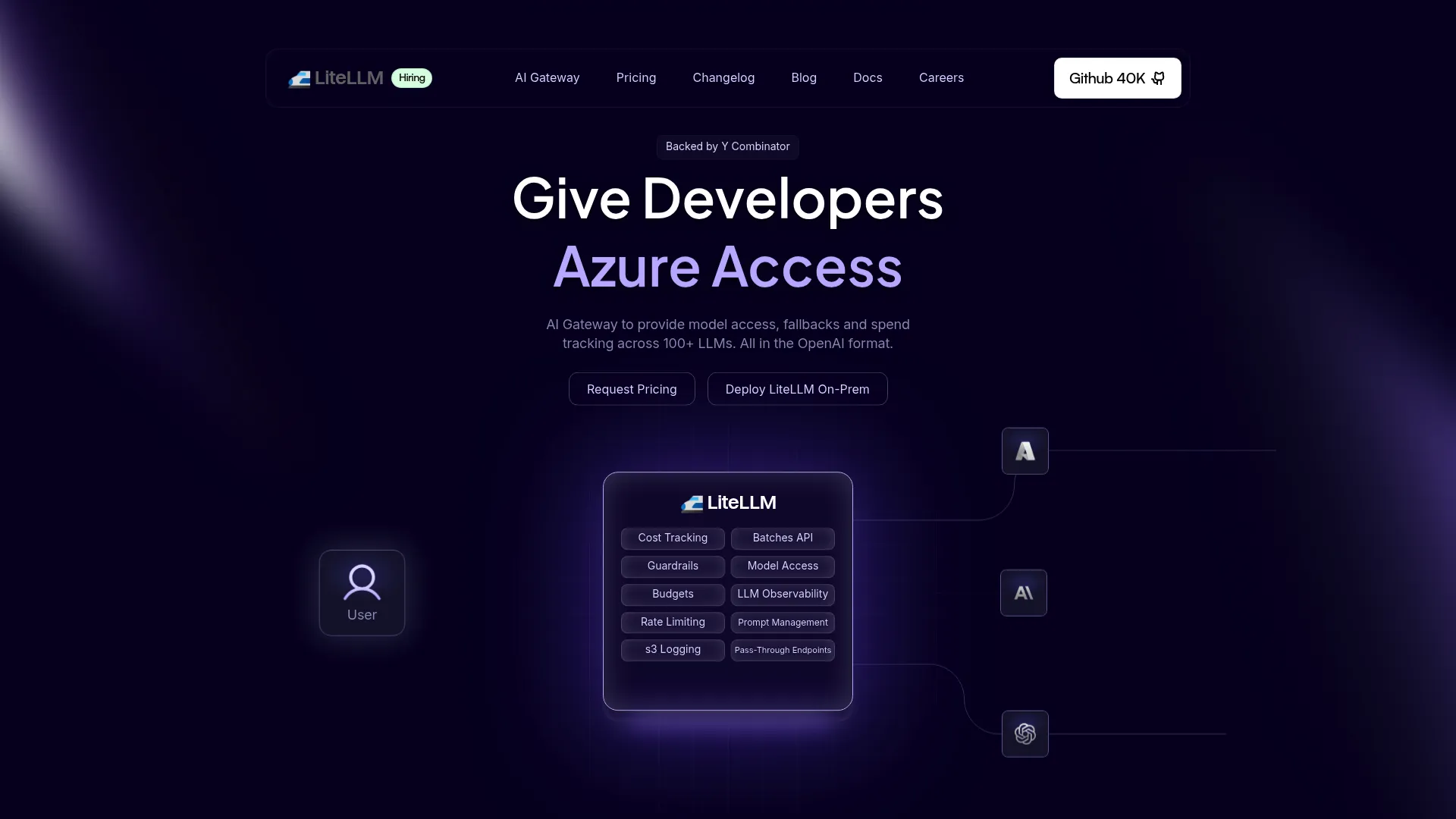
LiteLLM is an open-source AI gateway for routing, tracking, and governing access to multiple LLM providers through an OpenAI-compatible interface. It handles spend tracking, budgets, and rate limits, plus logging, guardrails, and virtual keys. For multi-provider setups, it sits as the abstraction layer between your apps and every model behind them.
This is infrastructure, not just developer convenience. A single OpenAI-compatible endpoint that fronts many providers lets you route, fall back, and switch models without rewriting application code, while virtual keys and budgets give platform teams governance over who calls what and how much they spend. For organizations standardizing model access across teams, that control is the point.
Best for: teams that need a self-hosted AI gateway with governance and routing across multiple LLM providers.
Key strengths
- OpenAI-compatible gateway: Front many providers behind a single, drop-in compatible endpoint.
- Spend and budget controls: Track cost and enforce budgets and rate limits per key.
- Governance features: Manage virtual keys, logging, and guardrails across teams.
Why choose LiteLLM: LiteLLM is the fit when you run multiple providers and need a routing and governance layer that does not lock you into one vendor. As an open-source gateway, it gives platform teams provider abstraction, fallback logic, and centralized spend control.
LiteLLM pricing: The Open Source plan is free and self-hostable. Enterprise pricing is available on request for self-hosted or cloud deployments with added support and features. As a newer open-source project, it does not yet carry a standard G2 product rating.
Considerations
Before you commit to an llmops platform, run your shortlist through this checklist. Most teams end up combining two or three tools rather than buying one monolith, so fit across layers matters more than any single feature.
Evaluation depth
Verify the tool can build datasets from real production traffic, run the same evals offline and online, and support both LLM-as-a-judge and code-based scoring. Evaluation-first development only works if the eval suite reflects reality, not synthetic test cases.
Observability depth
Look past dashboards to trace-level debugging. You want span-level traces, token cost attribution, prompt lineage, and agent-step visibility. The real test is whether you can replay the exact sequence behind a single bad response, not just read aggregate latency charts.
Governance controls
If multiple teams share infrastructure, prioritize role-based access control, audit logs, routing, and budget guardrails. Governance and safety expectations, including SSO and data retention controls, should be checked against your compliance requirements early, not after procurement stalls.
Deployment model and stack fit
Decide whether you need managed, self-hosted, or hybrid, then confirm framework compatibility, latency overhead, and integration depth with your existing stack. Production readiness comes down to whether the tool slots into your orchestration and data tooling without friction. Developer experience matters here: a tool your engineers actually adopt beats a more capable one they avoid.
Conclusion
There is no single best llmops platform, and any vendor claiming otherwise is selling. The category splits by layer, and the right answer depends on which layer hurts most right now.
If evaluation is your gap, Braintrust and Galileo AI lead on turning quality into a measurable, operational discipline. If you need observability and tracing, LangSmith, Langfuse, and PostHog give you trace-level visibility, with PostHog standing out for teams already on product analytics. If your priority is infrastructure, TrueFoundry and LiteLLM own the AI gateway and routing layer. And if you want open-source control across the whole lifecycle, MLflow and Langfuse let you self-host tracing, evaluation, and prompt management.
Most production teams will assemble a combination: an evaluation tool, a tracing layer, and a governance or gateway layer that work together. Start by naming the layer that is causing the most pain, pick the tool that owns it, and expand from there. Production readiness is earned one layer at a time, not bought in a single license.
FAQs
LLMOps is the operational layer for building, evaluating, deploying, monitoring, and continuously improving applications built on large language models. It covers prompt management, llm evaluation, tracing, production monitoring, and governance as a connected lifecycle rather than separate tasks.
MLOps manages deterministic models with clear accuracy metrics, while LLMOps deals with non-deterministic outputs that resist simple pass/fail grading. LLMOps adds prompt versioning workflows, LLM-as-a-judge evaluation, and agent tracing across multi-step workflows, which classic MLOps pipelines were never built to handle.
Evaluation-first tools like Braintrust and Galileo AI lead here, with Braintrust turning production logs into test suites and Galileo packaging evaluators with runtime guardrails. MLflow, Langfuse, and Weights & Biases also provide strong evaluation with LLM judges and code-based scoring, especially for teams that want it bundled with tracing.
Teams need trace-level visibility into prompts, agent steps, and token cost, which is where LangSmith, Langfuse, and PostHog stand out. LangSmith is particularly strong for agent workflows, Langfuse offers open infrastructure with self-hosting, and PostHog folds tracing into a full product analytics platform.
You need an AI gateway when multiple teams share model infrastructure and you want centralized routing, policy control, and cost management. Tools like TrueFoundry and LiteLLM provide gateway capabilities that route requests across providers, enforce budgets, and govern access, which becomes worth it once provider sprawl and spend get hard to track by hand.
Yes, open-source LLMOps tools work in production when your team can own deployment, monitoring, and governance. MLflow, Langfuse, and LiteLLM are self-hostable and widely run in production, giving you data control and no vendor lock-in in exchange for the engineering capacity to operate them. Many also offer managed versions if you prefer to skip the infrastructure work.
Quality scores, regression rates, latency, token cost, and task success are the metrics that matter most. Quality and regressions tell you whether changes help or hurt, latency and token cost govern user experience and budget, and task success measures whether the app actually does its job. RAG evaluation adds retrieval quality metrics when your app depends on grounded context.
Teams prevent prompt regressions with prompt versioning, offline eval suites run before every deploy, and production monitoring that catches drift the offline tests miss. The pattern is to version every prompt, score each change against a regression test built from real traffic, and roll back fast when a new version underperforms an old behavior.










