

Your model hit 94% accuracy in the notebook. Then it sat for three weeks while you figured out how to ship it. Sound familiar?
This is the gap every ML team knows. Models that work in a notebook stall on the way to production. The stack is fragmented. Retraining is manual and fragile. Drift goes unnoticed until a stakeholder asks why the predictions look wrong. Reproducing a result from last quarter means archaeology through Slack and old commits.
MLOps tools exist to close that gap. They cover the operational layer around machine learning: versioning data and models, tracking experiments, orchestrating pipelines, serving models, and monitoring them once they are live. Done well, they turn one-off model builds into a repeatable system.
The hard part is not knowing the categories. It is deciding how to assemble them. The single biggest decision is open source versus managed. Open source MLOps gives you control and zero licensing cost, but you run the infrastructure. A managed mlops platform gives you speed and support, at a price and with some lock-in. Most real stacks land somewhere in between.
This guide maps the 25 best MLOps tools for 2026 by lifecycle stage, tags each as open source, managed, or both, and gives you concrete stack recommendations by team maturity. The goal is a decision, not another link dump. If you're evaluating a broader software stack, our roundup of the best AI orchestration platforms is a useful companion read.
What's inside
This guide is for ML engineers, MLOps engineers, data scientists who own models end to end, and ML platform leads evaluating or maturing a production stack. It assumes you already know what experiment tracking and model serving are.
We selected the 25 tools on four criteria:
- Lifecycle coverage and category fit. Does the tool own a clear stage of the ML lifecycle?
- Adoption and support. Strong community traction or credible vendor backing.
- Integration with common stacks. Works with Kubernetes, major clouds, Git, and Python.
- Maturity and production-readiness. Used in real production systems, not just demos.
Tools are grouped by lifecycle stage, with an open-source-versus-managed lens applied throughout.
TL;DR
Short on time? Here are the shortcuts by need:
- Best open-source experiment tracking: MLflow. The de facto standard, free, and self-hostable.
- Best for Kubernetes-native teams: Kubeflow. Pipelines, serving, and tuning on K8s.
- Best for data and model versioning: DVC for Git-style workflows, lakeFS for data-lake scale.
- Best managed experiment tracking: Weights & Biases. Strong free tier, rich visualizations.
- Best for model monitoring: Evidently AI. Open-source-first ML and LLM observability.
- Best for LLMOps workflows: LangChain plus LangSmith for building and observing agents, with Qdrant for vector storage.
Open source for control, managed for speed, hybrid for most teams.
Background: what are MLOps tools?
MLOps tools are software for building, deploying, monitoring, and maintaining machine learning models in production. They operationalize the full ML lifecycle so that models stay reproducible, reliable, and easy to update as data and code change.
A complete MLOps software stack maps to these lifecycle stages:
- Data and pipeline versioning. Track datasets, features, and pipeline definitions alongside code.
- Experiment tracking and model registry. Log runs, parameters, and metrics, and version models through their lifecycle.
- Workflow orchestration. Automate and schedule the machine learning pipeline tools that connect each step.
- Feature stores. Keep features consistent between training and serving.
- Model testing, validation, and explainability. Catch data and model issues before and after deployment.
- Model deployment and serving. Package models and expose them as reliable inference endpoints.
- Model monitoring and observability. Detect drift, performance decay, and data quality problems in production.
- LLMOps and generative AI tooling. Manage prompts, RAG pipelines, vector storage, evaluation, and LLM observability.
- End-to-end managed platforms. Cover most of the above in one mlops platform.
A quick contrast helps. MLOps is DevOps plus the parts that make ML different. DevOps versions and ships code. An mlops framework adds data versioning, model versioning, retraining, and drift monitoring, because ML systems depend on changing data, not just static code. That extra surface area is exactly what these tools manage.
The market reflects this. In 2026, vendor and community roundups from sources like DataCamp and lakeFS consistently frame the category around the same lifecycle buckets: tracking, versioning, orchestration, serving, and monitoring. The disagreement is rarely about the stages. It is about whether you build with open source or buy a managed platform.
Open source vs managed MLOps: how to think about it
This is the decision that shapes everything else. Three patterns cover most teams.
Choose open source when you want control and have engineering depth
Open source MLOps gives you full control of the stack and zero licensing cost. You can inspect the code, customize behavior, and avoid vendor lock-in. The trade is operational: you provision the infrastructure, handle upgrades, and own uptime. This fits teams with real platform engineering capacity.
Choose a managed platform when you want speed and less ops overhead
A managed mlops platform gives you faster time-to-value, vendor support, and built-in governance. You skip the infrastructure work and get a console, SLAs, and security features out of the box. The cost is higher spend and some lock-in to that vendor's way of doing things. This fits teams that want to ship models, not run platforms.
Most real stacks are hybrid
In practice, very few teams pick one side cleanly. A common pattern is open-source experiment tracking and data versioning paired with a managed serving or platform layer. You keep control where flexibility matters and buy speed where undifferentiated ops would slow you down.
Here is the short version:
| Factor | Open source | Managed |
|---|---|---|
| Cost | Free license, you pay for infra and time | Subscription or usage-based |
| Control | Full, customizable | Constrained to vendor design |
| Maintenance | You own it | Vendor handles it |
| Time-to-value | Slower to stand up | Faster to start |
| Support | Community | Vendor SLAs |
Comparison table
All 25 tools, ordered by lifecycle stage to match the sections below. Many MLOps tools are open source and free to self-host, so several rows show "Open source (free)" honestly rather than a list price. Managed tiers and platforms are paid, usually seat- or usage-based. G2 ratings reflect current listings; some tools have too few reviews to show a meaningful score.
| # | Product | Intent (lifecycle stage) | Key use case | Pricing | G2 rating |
|---|---|---|---|---|---|
| 1 | MLflow | Experiment tracking and registry | Open-source tracking, registry, and model lifecycle | Open source (free) | Not enough reviews |
| 2 | Weights & Biases | Experiment tracking | Managed tracking, sweeps, and reports | Free; Pro from $60/mo | 4.7/5 |
| 3 | Comet ML | Experiment tracking and model management | Tracking, datasets, registry, LLM eval | Free; Pro $19/user/mo | 4.3/5 |
| 4 | Neptune.ai | Experiment tracking metadata | Large-scale run tracking and comparison | Startup from $150/user/mo | 4.6/5 |
| 5 | DVC | Data and model versioning | Git-style versioning of data and models | Open source (free) | 4.7/5 |
| 6 | lakeFS | Data versioning | Git-like version control over object storage | Open source; Enterprise custom | Not enough reviews |
| 7 | Pachyderm | Data pipelines and versioning | Versioned, lineage-tracked data pipelines | Enterprise (HPE) | 4.4/5 |
| 8 | DagsHub | ML project hub | Git, DVC, and MLflow in one platform | Free; Team $99/user/mo (yearly) | 4.8/5 |
| 9 | Kubeflow | Orchestration | Kubernetes-native ML pipelines and serving | Open source (free) | 4.5/5 |
| 10 | Metaflow | Orchestration | Python-native workflows from prototype to prod | Open source (free) | 4.5/5 |
| 11 | Prefect | Orchestration | Modern workflow orchestration | Free; Starter $100/mo | 4.5/5 |
| 12 | Dagster | Orchestration | Asset-based data and ML orchestration | Solo $10/mo; Pro custom | 4.5/5 |
| 13 | Apache Airflow | Orchestration | Battle-tested workflow scheduling | Open source (free) | 4.4/5 |
| 14 | Kedro | Pipeline framework | Reproducible Python pipeline structure | Open source (free) | No G2 listing |
| 15 | Feast | Feature store | Training-serving feature consistency | Open source (free) | No G2 listing |
| 16 | Featureform | Feature store | Features as code, real-time serving | Open source; Enterprise custom | 4.5/5 |
| 17 | Deepchecks | Testing and validation | Model, data, and LLM validation | Basic, Scale, Enterprise tiers | 4.4/5 |
| 18 | Ray | Distributed compute | Scale training, serving, and tuning | Open source (free) | 4.3/5 |
| 19 | BentoML | Model serving | Package and serve models in production | Pay-as-you-go from $0.0484/hr | 5.0/5 |
| 20 | Hugging Face | Model hub and inference | Models, datasets, managed endpoints | Free; Pro $9/mo | 4.9/5 |
| 21 | Nuclio | Serverless inference | Serverless functions for real-time ML | Open source (free) | Not enough reviews |
| 22 | Evidently AI | Model monitoring | ML and LLM monitoring and reports | Open source; Pro $80/mo | Not enough reviews |
| 23 | Fiddler AI | Model monitoring | Performance management and explainability | Free; Developer $0.002/trace | 4.3/5 |
| 24 | LangChain + LangSmith | LLMOps | Build and observe LLM apps and agents | Developer free; Plus $39/seat/mo | 4.7/5 |
| 25 | Qdrant | Vector database | Vector search for RAG and semantic search | Free tier; usage-based | 4.5/5 |
Group A: Experiment tracking and model registry
1. MLflow
MLflow is the open-source standard for experiment tracking and model management. It logs parameters, metrics, artifacts, and models, then versions them through a registry with lineage tracking. In 2026 it has expanded into observability and tracing for LLM and agent applications, so it spans classic ML and generative workloads. It is also available as a managed offering through Databricks, which removes the hosting burden.
Best for: Teams that want a free, widely adopted tracking and registry layer they can self-host.
Key strengths
- Observability and tracing: Trace LLM applications and agents alongside classic runs.
- Experiment tracking: Log parameters, metrics, artifacts, and models in one place.
- Model Registry: Version models with lifecycle management and lineage.
Why choose MLflow: MLflow is the safe default because nearly every other tool integrates with it. Self-host it for full control and zero licensing cost, or use the Databricks-managed version when you would rather not run the tracking server yourself. That open-source-or-managed flexibility is exactly why it anchors so many stacks.
MLflow pricing: MLflow is 100% open source under Apache 2.0 and free to self-host, with no licensing cost. Managed MLflow is available through Databricks as part of that platform, priced separately by Databricks. MLflow has too few G2 reviews to show a rating.
2. Weights & Biases
Weights & Biases is a managed AI developer platform built around experiment tracking and visualization. It handles run logging, hyperparameter sweeps, and shareable reports, and its Weave layer adds tracing, evaluations, and monitoring for AI applications. It is one of the most polished tracking experiences in the category.
Best for: ML and AI teams that want rich, managed tracking and collaboration without running infrastructure.
Key strengths
- Experiment tracking and visualization: Compare runs with strong charts and dashboards.
- Weave for AI apps: Tracing, evaluations, scorers, and monitoring for LLM workflows.
- Registry with lineage: Version models, datasets, prompts, code, and metadata.
Why choose Weights & Biases: Pick W&B when you want managed speed and best-in-category visualization over self-hosting. It contrasts with MLflow as the buy-not-build option for tracking. The free tier lets individuals and small teams start at no cost before scaling up.
Weights & Biases pricing: The Free plan is $0/month. Pro starts at $60/month billed monthly. Enterprise is custom, and privately hosted Personal and Advanced Enterprise plans are also offered. It holds a 4.7/5 rating on G2.
3. Comet ML
Comet ML is a managed MLOps and GenAI evaluation platform. It covers experiment tracking, dataset versioning, a model registry, and production monitoring, plus LLM evaluation through its Opik tooling. It is a strong all-in-one option for teams that want tracking and lightweight model management together.
Best for: ML teams that want managed experiment tracking with model lineage and LLM evaluation in one place.
Key strengths
- Experiment tracking: Record, compare, and analyze training runs.
- Dataset and model versioning: Link data to experiments for reproducibility.
- LLM evaluation: Tracing, LLM-as-a-judge metrics, and production monitoring.
Why choose Comet ML: Comet fits teams that want a managed alternative to MLflow with built-in dataset management and LLM evaluation. The free tier covers solo work, and the per-user Pro plan keeps pricing predictable for small teams. Enterprise adds the deployment flexibility and compliance controls larger orgs need.
Comet ML pricing: The Free plan is $0 and includes experiment tracking, dataset management, and the Model Registry for one user. Pro is $19 per user/month for up to 10 users with 1,500 training hours included. Enterprise is custom. Comet ML holds a 4.3/5 rating on G2.
4. Neptune.ai
Neptune.ai is an experiment tracker focused on foundation-model and large-scale training. It is built to monitor, visualize, compare, and debug runs at scale, including per-layer metrics like losses, gradients, and activations. It also offers a self-hosted deployment for teams that need to run on their own infrastructure.
Best for: Teams training large or foundation models that need to compare thousands of runs and debug at the layer level.
Key strengths
- Layer-level metrics: Track losses, gradients, and activations across layers.
- Scale comparison: Compare thousands of runs in one view.
- Self-hosted option: Deploy on your own infrastructure or private cloud.
Why choose Neptune.ai: Neptune shines at the scale where generic trackers struggle: large training jobs with deep, granular metrics. It is managed by default with a self-hosted path, so you can keep control when compliance requires it. Choose it when run volume and debugging depth matter most.
Neptune.ai pricing: The Startup plan starts at $150 per user/month, billed monthly with a discount on annual plans, and includes unlimited tracked hours, users, and projects. The Lab plan is $250 per user/month and adds higher data limits and priority support. A Self-hosted plan is available via sales. Neptune.ai holds a 4.6/5 rating on G2.
Group B: Data and pipeline versioning
5. DVC
DVC brings Git-style version control to data and models. It tracks datasets, models, metadata, and pipeline definitions, so you can reproduce any experiment from a commit. It pairs naturally with Git for code, giving you a single mental model across your repository. DVC Studio adds a hosted view for collaboration on top of the open-source core.
Best for: Individual data scientists and ML teams that want Git-based versioning for data, models, and pipelines.
Key strengths
- Data and model versioning: Track large files with Git-like semantics.
- Data pipelines: Define reproducible, dependency-aware pipeline stages.
- Experiment management: Capture and compare experiments tied to commits.
Why choose DVC: DVC is the open-source answer to data reproducibility for teams that already live in Git. It is free and self-hosted, so you pay in setup rather than license. Use it when versioned data and reproducible pipelines are the gap, and pair it with MLflow for tracking.
DVC pricing: DVC for local workflows is free and open source. There is no paid plan to buy for the core tool. DVC holds a 4.7/5 rating on G2.
6. lakeFS
lakeFS brings Git-like version control to object storage and data lakes. It adds branching, merging, and reproducibility on top of formats you already use, without copying the data. Zero-copy branching lets you spin up isolated environments instantly, and hooks enable data CI/CD. It is built for scale that file-level tools do not reach.
Best for: Data and ML engineering teams that need versioning, branching, and governance over large data lakes.
Key strengths
- Format-agnostic versioning: Version data regardless of underlying format.
- Zero-copy branching: Create isolated environments without duplicating data.
- Data CI/CD: Validate data changes with lakeFS hooks before promotion.
Why choose lakeFS: lakeFS fits when your data lives in object storage at a scale where DVC's file model is the wrong fit. The open-source version is free forever, and an Enterprise tier adds governance and support. Choose it for data-lake reproducibility and atomic promotion via merges.
lakeFS pricing: The Open Source plan is free forever. The Enterprise plan offers unlimited seats and requires contacting sales for a quote. lakeFS does not yet have enough G2 reviews to show a rating.
7. Pachyderm
Pachyderm, now part of HPE Machine Learning Data Management Software, is a data science platform for reproducible, version-controlled pipelines. Pipelines are triggered by changes to data, and every run produces immutable lineage. It is language-agnostic and runs on Kubernetes, which makes it a fit for engineering-heavy teams.
Best for: Data engineering and ML teams that need reproducible, version-controlled pipelines with automatic lineage.
Key strengths
- Data-driven pipelines: Trigger pipeline runs automatically on data changes.
- Immutable lineage: Track every input, output, and parameter for audit.
- Data versioning: Version files, metadata, code, and generated artifacts.
Why choose Pachyderm: Pachyderm fits teams that want data-driven pipelines with strong lineage on Kubernetes. It now sits inside HPE's enterprise licensing, so it is a managed, enterprise-oriented choice rather than a lightweight open-source pick. Evaluate current availability with HPE before committing.
Pachyderm pricing: Pricing follows HPE's enterprise licensing model, sold as multi-year subscription licenses with no public price amounts listed. Confirm current terms and availability directly with HPE. Pachyderm holds a 4.4/5 rating on G2.
8. DagsHub
DagsHub is a managed hub that brings Git, DVC, and MLflow together for ML projects. It handles multimodal dataset curation and annotation, experiment tracking, and model management in one place. Think of it as a collaboration platform that ties your code, data, and experiments into a single project view.
Best for: ML teams that want one managed home for datasets, annotations, experiments, and model versions.
Key strengths
- Multimodal data management: Curate, query, visualize, and annotate datasets.
- MLflow-compatible tracking: Track experiments and compare metrics and parameters.
- Model management: Connect model versions to experiments, data, and code.
Why choose DagsHub: DagsHub is the managed glue for teams that want DVC and MLflow without standing up each piece themselves. The free Individual tier suits small projects, while Team and Enterprise add collaboration, RBAC, and scale. Choose it to reduce the assembly cost of an open-source data stack.
DagsHub pricing: The Individual plan is $0 per user/month. Team is $119 per user/month billed monthly, or $99 per user/month billed yearly, and adds private repositories, annotation, and up to 1TB of data. Enterprise is a custom quote with petabyte-scale management and on-prem options. DagsHub holds a 4.8/5 rating on G2.
Group C: Workflow orchestration and machine learning pipeline tools
9. Kubeflow

Kubeflow is the foundation of machine learning pipeline tools for Kubernetes. It bundles Pipelines for portable workflows, Trainer for distributed training and fine-tuning, Katib for hyperparameter tuning, and KServe for serving. If your infrastructure is already Kubernetes, Kubeflow keeps your ML lifecycle native to it.
Best for: AI platform teams that want composable, Kubernetes-native tools for the full ML workflow.
Key strengths
- Kubeflow Pipelines: Build and deploy portable, scalable workflows on Kubernetes.
- Distributed training: Train and fine-tune across frameworks with Kubeflow Trainer.
- Automated tuning: Run hyperparameter search and NAS with Katib.
Why choose Kubeflow: Kubeflow is the natural pick when Kubernetes is your platform and you want open-source control end to end. It rewards teams with K8s expertise and asks for that expertise in return. Choose it to keep training, tuning, and serving inside one open ecosystem.
Kubeflow pricing: Kubeflow is open source and free to deploy on your own Kubernetes cluster, with no licensing cost. Your spend is the underlying compute and the engineering to run it. Kubeflow holds a 4.5/5 rating on G2.
10. Metaflow
Metaflow is an open-source Python framework for building, scaling, and deploying ML and data science projects. Built originally at Netflix, it is designed to feel natural to data scientists: write workflows in Python, test locally, then scale to the cloud or Kubernetes. It tracks and versions flows and artifacts automatically.
Best for: Data science teams that want a Python-native path from prototype to production on their own infrastructure.
Key strengths
- Python-native workflows: Develop and debug flows locally in plain Python.
- Automatic versioning: Track flows, experiments, and artifacts without extra work.
- Scale to cloud: Move compute to cloud accounts and Kubernetes clusters.
Why choose Metaflow: Metaflow lowers the orchestration learning curve for data scientists who would rather not become infrastructure engineers. It is open source and free, with managed support available commercially if you want it. Choose it when developer ergonomics matter as much as scale.
Metaflow pricing: Metaflow is open source and free to use. A first-party public pricing page for managed offerings was not available at the time of writing. Metaflow holds a 4.5/5 rating on G2.
11. Prefect
Prefect is a modern workflow orchestration platform for Python teams. It handles scheduling, observability, logging, and alerting, with governance features like SSO and RBAC on higher tiers. The open-source core is free, and Prefect Cloud adds a managed control plane.
Best for: Python-focused teams that need managed orchestration with strong observability and production governance.
Key strengths
- Workflow scheduling: Schedule and run pipelines reliably.
- Observability: Built-in logging and alerting for workflow runs.
- Governance: Automations, SSO, RBAC, and audit logs on higher tiers.
Why choose Prefect: Prefect appeals to teams that find older schedulers heavy and want a Pythonic, modern feel. Run the open-source version for control, or buy Prefect Cloud for the managed control plane and governance. That open-source-or-managed split makes it flexible as you scale.
Prefect pricing: The Hobby plan is free forever. Starter is $100/month, and Team is $100 per user/month. Pro and Enterprise are custom-priced annual plans. Prefect holds a 4.5/5 rating on G2.
12. Dagster
Dagster is an asset-based orchestration platform for data and ML pipelines. Instead of orchestrating tasks in isolation, it models the data assets your pipelines produce, with lineage, quality signals, and dependency context built in. Its hybrid deployment runs compute in your infrastructure while Dagster manages the control plane.
Best for: Data engineering and platform teams that want asset-centric orchestration with observability and lineage.
Key strengths
- Asset-centric orchestration: Model assets with lineage and dependency context.
- Built-in observability: Real-time monitoring and asset health dashboards.
- Hybrid deployment: Keep compute in your infrastructure, control plane managed.
Why choose Dagster: Dagster fits teams that think in data assets rather than tasks and want lineage as a first-class concept. The open-source core gives control, and Dagster+ adds managed convenience. Choose it when observability and asset lineage are central to how you operate.
Dagster pricing: The Solo plan is $10/month plus pay-as-you-go credits. The Starter plan is $100/month plus credits. The Pro plan is contact-sales. Dagster+ Serverless compute is billed at $0.010 per minute. Dagster holds a 4.5/5 rating on G2.
13. Apache Airflow
Apache Airflow is the open-source orchestration workhorse for batch workflows. You define pipelines as Python code, monitor them through a web UI, and connect to clouds and services through a large library of operators. It is mature, widely deployed, and well understood across the industry. Astronomer offers a managed version for teams that prefer not to self-host.
Best for: Data engineering teams that want to define, schedule, and monitor batch workflows as Python code.
Key strengths
- Python authoring: Define workflows as code with full flexibility.
- Web UI: Monitor, schedule, manage, and debug workflows visually.
- Operators and integrations: Plug into cloud platforms and third-party services.
Why choose Apache Airflow: Airflow is the safe, proven choice when you need a general-purpose scheduler with a deep operator library and a large talent pool. Self-host it for control, or use Astronomer for a managed experience. Choose it when maturity and ecosystem breadth outweigh newer ergonomics.
Apache Airflow pricing: Airflow is open source and free to self-host, with no licensing cost. Managed Airflow is available through Astronomer and cloud providers, priced separately. Apache Airflow holds a 4.4/5 rating on G2.
14. Kedro
Kedro is an open-source Python framework for building production-ready data science pipelines. It is less an orchestrator and more a structure: project templates, a Data Catalog, and pipeline abstractions that make code modular and reproducible. Kedro-Viz visualizes data lineage and pipeline execution so the structure stays legible.
Best for: Data science and engineering teams that want a standardized, reproducible structure for Python pipelines.
Key strengths
- Pipeline visualization: See data lineage and execution with Kedro-Viz.
- Data Catalog: Load and save data across many formats and file systems.
- Project templates: Standardize modular, reproducible pipeline code.
Why choose Kedro: Kedro pairs well with an orchestrator like Airflow or Prefect rather than replacing one. It is open source and free, and it earns its place by enforcing structure on otherwise messy notebooks-to-production code. Choose it when code consistency across a team is the problem.
Kedro pricing: Kedro is an open-source project and free to use, installed via pip or conda. There is no paid plan for the framework itself. A current product rating for Kedro was not available on major review sites at the time of writing.
Group D: Feature stores
15. Feast

Feast is an open-source feature store for serving structured data to ML applications during training and inference. Its core job is consistency: the same feature definitions feed both your training pipeline and your low-latency online serving. That training-serving parity is what prevents subtle skew bugs in production.
Best for: ML platform teams that need an open-source feature store for consistent features across training and serving.
Key strengths
- Offline and online serving: Support training data and low-latency inference.
- Python SDK: Define, read, and write features in code.
- Feature server: Retrieve and update features in real time.
Why choose Feast: Feast is the open-source default when training-serving consistency is your gap and you want a vendor-neutral feature layer. It is free and self-hosted, so you integrate it into your own infrastructure. Choose it when feature reuse and parity matter across multiple models.
Feast pricing: Feast is open source and free to self-host. There is no first-party paid plan for the core project. A current product rating for Feast was not available on major review sites at the time of writing.
16. Featureform
Featureform is a feature store that lets you define ML features as code and turn them into production data pipelines. It orchestrates pipelines across your offline data systems and online serving, with enterprise controls like workspace-scoped RBAC and audit logs. It is now associated with Redis for online serving.
Best for: Enterprise AI and ML teams that need a feature store integrated with existing data infrastructure.
Key strengths
- Features as code: Define features once for training and inference.
- Pipeline orchestration: Coordinate offline systems and online serving.
- Enterprise controls: Workspace RBAC, audit logs, and secure access.
Why choose Featureform: Featureform fits teams that want a feature store that sits on top of infrastructure they already run, with enterprise governance. It offers open-source and enterprise paths, so you can start free and grow into managed controls. Choose it when governance and real-time serving are both requirements.
Featureform pricing: Featureform lists Open-Source and Enterprise options, with the open-source version free to use and Enterprise priced on a quote basis. No public numeric price was listed at the time of writing. Featureform holds a 4.5/5 rating on G2.
Group E: Model testing, validation, and explainability
17. Deepchecks
Deepchecks is a validation and evaluation platform for ML and LLM applications. It runs automated checks on models and data, and for LLM and agentic apps it scores quality dimensions like hallucination likelihood, answer relevance, instruction following, and toxicity. It supports version comparison across prompts, models, and retrieval strategies.
Best for: Teams building production LLM, RAG, or agentic apps that need automated evaluation and monitoring.
Key strengths
- Automatic quality metrics: Score hallucination, relevance, and toxicity.
- Version comparison: Compare prompts, models, and retrieval strategies.
- Production monitoring: Track score distributions and property trends.
Why choose Deepchecks: Deepchecks fits teams that want validation and testing baked into the lifecycle rather than bolted on at the end. It offers open-source roots and managed tiers, so you can scale from local checks to enterprise monitoring. Choose it when evaluation rigor for LLM and ML apps is a priority.
Deepchecks pricing: Deepchecks lists Basic, Scale, and Enterprise tiers, with Basic covering up to 3 seats and one AI application, and Scale and Enterprise adding capacity, support, and compliance. Public numeric prices were not displayed at the time of writing. Deepchecks holds a 4.4/5 rating on G2.
18. Ray
Ray is an open-source framework for scaling AI, ML, and Python workloads from a laptop to a cluster. Ray Core distributes Python code through tasks, actors, and objects, while higher-level libraries handle data processing, training, tuning, reinforcement learning, and serving. It is the distributed-compute layer many other tools build on.
Best for: AI and ML engineering teams that need to scale training, serving, tuning, or batch inference across distributed compute.
Key strengths
- Distributed Python: Scale code with Ray Core tasks, actors, and objects.
- End-to-end workloads: Cover data, training, tuning, RL, and serving.
- Scale to GPUs: Run from a laptop to thousands of CPUs and GPUs.
Why choose Ray: Ray fits when raw scale is the bottleneck and you want one framework across the workload. It is open source and free, with a managed option through Anyscale when you would rather not run the cluster yourself. Choose it to scale compute without rewriting your code for each stage.
Ray pricing: Ray is open source and free to use. Managed Ray is available through Anyscale, priced separately. The associated Anyscale listing holds a 4.3/5 rating on G2.
Group F: Model deployment and serving
19. BentoML
BentoML is a unified inference platform for packaging, deploying, and scaling models. It supports open-source and custom models across frameworks and modalities, with CI/CD, observability, and access control built in. Its serving layer handles elastic autoscaling, cold-start acceleration, and scale-to-zero, deployable on BentoCloud, your cloud, or on-prem.
Best for: AI and ML teams that need to deploy and scale custom or open-source model inference in production.
Key strengths
- Multi-framework serving: Deploy models across frameworks and modalities.
- Production tooling: CI/CD, observability, access control, and resource tracking.
- Elastic scaling: Autoscaling, cold-start acceleration, and scale-to-zero.
Why choose BentoML: BentoML fits teams that want serving and packaging handled without building it from scratch. The open-source core gives control, and BentoCloud offers managed compute with pay-as-you-go pricing. Choose it when reliable, scalable inference is the gap between your model and production.
BentoML pricing: The Starter plan is pay-as-you-go, with compute starting at $0.0484/hr for the smallest CPU instance and GPU options priced higher. Scale offers committed-use discounts, and Enterprise is custom for VPC and on-prem needs. BentoML holds a 5.0/5 rating on G2.
20. Hugging Face
Hugging Face is the collaboration platform for models, datasets, and applications, paired with managed inference. You can host and share models, access models through a unified Inference Providers API, and deploy dedicated Inference Endpoints for production serving. It is where a huge share of open models already live.
Best for: AI teams and developers that need to discover, share, and deploy models with managed inference.
Key strengths
- Model and dataset hub: Host and collaborate on public assets.
- Inference Providers: Access AI models through a unified API.
- Dedicated endpoints: Deploy models and apps with managed compute.
Why choose Hugging Face: Hugging Face fits teams building on open models that want hosting and managed inference without standing up serving infrastructure. The free tier and low entry price make experimentation cheap, with dedicated endpoints for production. Choose it when your models come from the open ecosystem.
Hugging Face pricing: Spaces CPU Basic is free. The Pro account is $9/month, Team is $20/month per user, and Enterprise is $50/month per user. Dedicated Inference Endpoints start at $0.033/hour. Hugging Face holds a 4.9/5 rating on G2.
21. Nuclio

Nuclio is an open-source and managed serverless platform for deploying data-science applications as functions. It targets real-time performance, with high-throughput function invocation, Kubernetes support, GPU support, and a management dashboard. It is a fit for low-latency inference, data processing, APIs, and edge workloads.
Best for: Data science and platform teams that need portable serverless functions for real-time AI and data workloads.
Key strengths
- High-performance functions: Serve real-time inference at high invocation rates.
- Kubernetes-native: Run and manage functions on Kubernetes.
- GPU and multi-tenancy: Support GPU workloads with basic monitoring and logging.
Why choose Nuclio: Nuclio fits teams that want serverless, event-driven inference without giving up control. It is open source and free to run, with a managed path through Iguazio for teams that want it. Choose it when real-time, function-based serving suits your workload better than always-on services.
Nuclio pricing: Nuclio is open source and free to self-host. A managed experience is available through Iguazio, priced separately. Nuclio does not have enough public reviews to show a meaningful rating.
Group G: Model monitoring and observability (model monitoring tools)
22. Evidently AI
Evidently AI is an open-source-first platform for evaluating, testing, and monitoring ML models, LLMs, RAG apps, and AI agents. It offers more than 100 built-in metrics, synthetic data generation for edge-case testing, and continuous monitoring dashboards for drift, quality, and regressions. As one of the more popular model monitoring tools, it spans classic ML and generative workloads.
Best for: AI teams that want open-source-first evaluation, testing, and monitoring across ML and LLM systems.
Key strengths
- Automated evaluation: Score quality with 100+ built-in metrics.
- Synthetic data generation: Create realistic, edge-case, and adversarial inputs.
- Continuous monitoring: Dashboards for drift, quality checks, and regressions.
Why choose Evidently AI: Evidently is the open-source default for drift detection and monitoring, which is why it leads this category. Self-host the open-source version for control, or use Evidently Cloud for the managed experience. Choose it when you want monitoring you can inspect and extend.
Evidently AI pricing: The Open-source and Developer plans are free. Pro is listed at $80/month with capacity limits and email support, and Enterprise is custom. A Startups offer is also available. Evidently AI does not yet have enough G2 reviews to show a rating.
23. Fiddler AI
Fiddler AI is an AI observability and security platform for monitoring, protecting, and governing models and agentic systems. It combines real-time guardrails, unified observability for agentic and predictive systems, and explainability with custom evaluators. It is built for enterprise teams that need governance alongside monitoring.
Best for: Enterprise teams deploying AI agents, LLM apps, or predictive ML that need observability, guardrails, and governance.
Key strengths
- Real-time guardrails: Catch hallucinations, toxicity, PII, and prompt injection.
- Unified observability: Monitor agentic and predictive systems together.
- Explainability: Custom evaluators, RBAC, SSO, and flexible deployment.
Why choose Fiddler AI: Fiddler fits enterprise teams where monitoring is not enough and governance and guardrails are required. It is managed by design, with deployment options spanning SaaS, VPC, and on-prem. Choose it when explainability and compliance sit alongside drift detection in your requirements.
Fiddler AI pricing: The Free plan includes real-time guardrails. The Developer plan is $0.002 per trace and adds unified observability, tests, and custom evaluators. Enterprise is contact-sales. Fiddler AI holds a 4.3/5 rating on G2.
Group H: LLMOps and generative AI tooling
24. LangChain + LangSmith
LangChain is an open-source framework for building agents, with pre-built architectures and a large library of integrations for models, tools, and databases. Its companion, LangSmith, adds the LLMOps layer: tracing, evaluation, prompt management, and monitoring for LLM applications. Together they cover building and operating agentic apps. Teams building agent workflows for go-to-market often pair these with the best AI sales tools and emerging agentic AI tools for sales.
Best for: Developers and teams building agentic LLM applications that need orchestration, tracing, and evaluation.
Key strengths
- Pre-built agent patterns: Start from common agent architectures.
- 1000+ integrations: Connect models, tools, and databases.
- Observability and eval: Trace, evaluate, and monitor LLM apps with LangSmith.
Why choose LangChain: LangChain plus LangSmith is the most direct path from prototyping an agent to observing it in production. LangChain is MIT-licensed and free, while LangSmith offers a free Developer tier and paid plans for teams. Choose it when LLM app development and LLMOps observability need to live together.
LangChain pricing: LangChain is open source and free under an MIT license. LangSmith's Developer plan is $0 per seat with pay-as-you-go usage, Plus is $39 per seat/month, and Enterprise is custom. LangChain holds a 4.7/5 rating on G2.
25. Qdrant

Qdrant is a high-performance vector database and search engine for AI retrieval at scale. It powers RAG, semantic search, recommendations, and agent memory, with rich metadata filtering, native hybrid search, and multivector retrieval. It is a core building block of the LLMOps stack.
Best for: Teams building production RAG, semantic search, recommendation, or agent memory systems that need scalable vector search.
Key strengths
- Rich metadata filtering: Filter with nested JSON, text, and geo conditions.
- Native hybrid search: Combine dense and sparse vectors, including BM25.
- Multivector retrieval: Store and query multiple vectors per object.
Why choose Qdrant: Qdrant fits teams that need fast, scalable vector retrieval as the backbone of their RAG or search system. The open-source engine gives control, and Qdrant Cloud offers a managed free tier and usage-based scaling. Choose it when retrieval performance and filtering flexibility matter.
Qdrant pricing: The Free Tier is free forever for testing and prototypes. The Standard Tier is usage-based and billed hourly for production workloads. The Premium Tier requires a minimum spend and adds security and compliance. Qdrant holds a 4.5/5 rating on G2.
When to use which MLOps tool: stack recommendations by team
The right mlops solution depends on team maturity more than on any single feature. Here are three concrete starting points.
Build a lean startup ML stack
Keep ops near zero. Use MLflow for experiment tracking and a model registry, DVC for data and model versioning, and a managed serving option like Hugging Face Inference Endpoints or BentoML's pay-as-you-go compute. You get reproducibility and deployment without running orchestration infrastructure yet. Add complexity only when a real bottleneck appears.
Scale a mid-market production stack
Now add the pieces that keep a growing system reliable. Introduce orchestration with Prefect, Dagster, or Apache Airflow. Add a feature store like Feast for training-serving consistency. Put monitoring in place with Evidently AI so drift surfaces before stakeholders notice. This is where the stack shifts from "it runs" to "it runs predictably."
Standardize an enterprise stack
At enterprise scale, governance and consistency dominate. A managed platform anchors the stack, layered with governance and Kubernetes-native components like Kubeflow and KServe for portable training and serving. Add Fiddler AI for observability and guardrails where compliance demands explainability. The goal is one standard the whole org can follow.
Here is the same guidance in a table:
| Team maturity | Recommended stack |
|---|---|
| Lean startup | MLflow + DVC + managed serving (Hugging Face or BentoML) |
| Mid-market | Add Prefect/Dagster/Airflow + Feast + Evidently AI |
| Enterprise | Managed platform + governance + Kubeflow/KServe + Fiddler AI |
Considerations: how to choose MLOps tools
Before you commit to any mlops software, run through this checklist.
Lifecycle coverage and stack fit
Map your current stack against the lifecycle stages above, then find your biggest gap. A tool that overlaps with what you already run adds maintenance without value. The best mlops solution is usually the one that closes a real gap cleanly.
Open source vs managed
Weigh cost, control, maintenance, and support honestly. Open source MLOps removes licensing cost but adds operational load. A managed platform removes ops but adds spend and some lock-in. Match the choice to your engineering capacity, not to what looks cheapest on paper.
Integration with your cloud, Kubernetes, and Git workflow
Check that the tool fits how you already work. Kubernetes-native teams gain from Kubeflow and KServe; Git-centric teams gain from DVC and lakeFS. A tool that fights your existing workflow rarely survives adoption. Whatever the stack, communicating its capabilities clearly matters too - many teams use interactive demos to onboard new engineers and stakeholders.
Reproducibility, governance, and compliance
For regulated or enterprise contexts, reproducibility and audit trails are not optional. Confirm the tool tracks lineage, versions data and models, and supports the access controls your org requires. This is where managed platforms and tools like Fiddler AI often earn their cost.
Scalability and team maturity
A startup and an enterprise need different stacks. Pick tools you can grow into, not tools that demand more ops than your team can sustain today. Right-size the mlops platform to where you are, with a clear path to where you are going. For teams comparing broader software categories, our best tools roundups cover adjacent platforms worth evaluating.
Conclusion
The MLOps landscape is large, but the decisions are not. For experiment tracking, MLflow leads the open-source side and Weights & Biases the managed side. For data versioning, DVC fits Git-centric teams and lakeFS fits data lakes. For orchestration, Kubeflow owns Kubernetes-native work while Prefect, Dagster, and Airflow cover general pipelines. For monitoring, Evidently AI leads open source and Fiddler AI brings enterprise governance. For LLMOps, LangChain with LangSmith plus Qdrant covers building, observing, and retrieval.
The spine through all of it stays the same. Open source for control and zero licensing cost. Managed platforms for speed, support, and governance. Hybrid for nearly every real team.
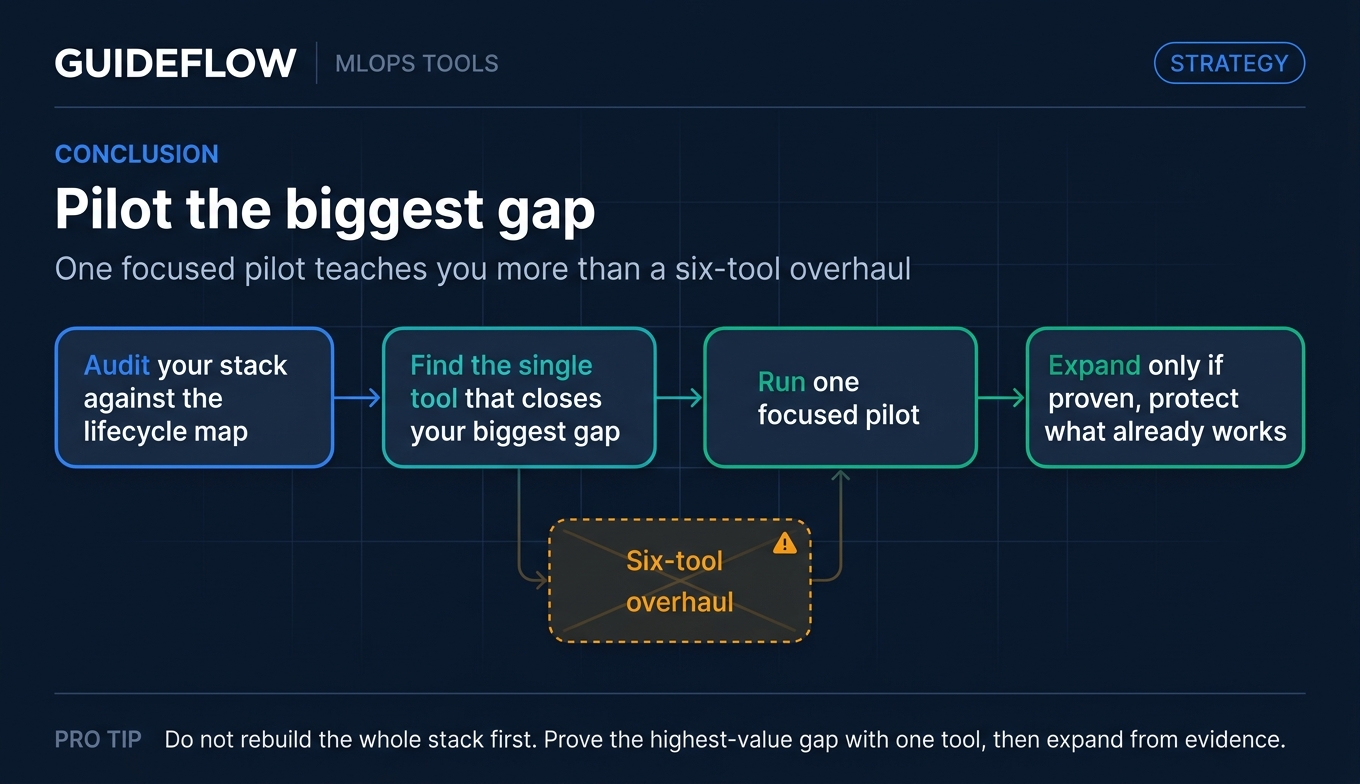
Start by auditing your stack against the lifecycle map above, then pilot the single tool that closes your biggest gap. One focused pilot teaches you more than a six-tool overhaul, and it protects the parts of your stack that already work. And when it's time to demonstrate your ML product to buyers or partners, a polished demo showcase can make the value land faster.
FAQ
MLOps tools are software that operationalize the machine learning lifecycle, including data and model versioning, experiment tracking, orchestration, serving, and monitoring. They turn one-off model builds into repeatable, reliable systems. They matter because they keep models reproducible and stable once they reach production.
DevOps versions and ships application code. MLOps extends DevOps with data versioning, model versioning, retraining, and drift monitoring, because ML systems depend on changing data, not just code. That extra surface area is why ML needs its own tooling.
Open source gives you control and zero licensing cost, but you run and maintain the infrastructure. Managed platforms give you speed, support, and governance at a higher cost and with some lock-in. Most teams run a hybrid, using open source where flexibility matters and managed where ops would slow them down.
There is no single winner; it depends on the lifecycle stage. MLflow leads open-source experiment tracking, DVC leads data versioning, Kubeflow leads orchestration on Kubernetes, and Evidently AI leads monitoring. Pick by the gap you need to fill.
Map your needs to lifecycle stages, then check fit with your cloud, Kubernetes, and Git workflow. Weigh open source versus managed against your engineering capacity. Factor in team maturity, reproducibility, and any compliance requirements before committing.
LLMOps tools handle prompt versioning, RAG pipelines, vector storage, evaluation, and observability of LLM applications. Examples include LangChain and LangSmith for building and observing agents, Deepchecks for evaluation, and vector databases like Qdrant for retrieval. They are the generative-AI layer alongside classic MLOps.
Many core tools are open source and free to self-host, including MLflow, DVC, Kubeflow, Feast, and Evidently AI. Your cost is the infrastructure and engineering to run them. Managed versions and end-to-end platforms are paid, usually priced by usage or seats.
A minimal stack covers three things: experiment tracking with MLflow, data versioning with DVC, and a deployment or serving option like Hugging Face or BentoML. Add orchestration and monitoring as you scale and real bottlenecks appear. Start small and grow the stack with your needs.










