

You need realistic data to test a new feature, train a model, or validate a workflow across segments. The data that would make that real sits in production, locked behind privacy rules, compliance reviews, and re-identification risk. So you wait on engineering to provision a sanitized copy, or you ship against thin, fragile test datasets that break the moment a schema changes.
That gap is exactly what synthetic data tools close. They generate artificial datasets that statistically mirror your real data, without exposing the real people behind it. Teams that need to showcase products on safe, realistic data also lean on tools like a Sandbox environment to let stakeholders explore without touching production.
The demand is not theoretical. Gartner, as cited by Tonic in 2026, predicts that 75% of businesses will use generative AI to create synthetic data by 2026, up from less than 5% in 2023. Market analysts also project the synthetic data generation market to grow at roughly 30 to 35% CAGR into the early 2030s, with the segment skewing heavily toward mid-market adoption rather than only the largest enterprises.
The problem most teams hit next is selection. The category spans free Python libraries, healthcare-specific generators, and enterprise platforms with referential integrity across dozens of systems. They are not interchangeable. Picking the wrong one means brittle test data, weak model performance, or a compliance gap you find during an audit.
This guide compares 15 synthetic data tools across AI, testing, and privacy, so you can match the tool to the job before you commit.
What's inside
This guide is for product managers, data and ML engineers, QA leads, and privacy owners who are building a shortlist of synthetic data generation tools. It covers free and open-source options alongside enterprise platforms, plus a buyer-decision framework so the list maps to your actual constraints.
We evaluated each tool against four criteria that matter most for this buyer:
- Data realism and referential integrity: does generated data preserve statistical patterns and relationships across tables?
- Privacy and compliance: masking, de-identification, and handling of PII and PHI under GDPR, CCPA, and HIPAA.
- Workflow integration and automation: APIs, SDKs, CI/CD fit, and self-service for technical and non-technical users.
- Ease of use: how fast a team reaches a usable dataset.
TL;DR
Short on time? Here are the decision shortcuts.
- Best for high-fidelity test data plus AI training data: Tonic.ai.
- Best for privacy-safe tabular synthetic data with a no-code interface: MOSTLY AI.
- Best developer-first, API-driven synthetic data generator: Gretel.
- Best for enterprise relational test data with referential integrity: K2view.
- Best free and open-source options: Synthetic Data Vault (SDV), Synthea, and Faker.
- Best for healthcare and clinical data: MDClone and Synthea.
- Best for fast, schema-based test datasets: Mockaroo.
Background: what are synthetic data tools?

Synthetic data tools generate artificial datasets that statistically mirror real data without exposing real personal information. Instead of copying or masking production records, a synthetic data generator learns the structure and statistical attributes of a source dataset, then produces new records that behave like the original but map to no real individual.
That distinction matters. Anonymization alters real records in place, which leaves a residual link back to people and a re-identification risk. Synthetic data is newly generated, so well-built datasets break that one-to-one mapping while preserving the patterns you actually need for testing and modeling.
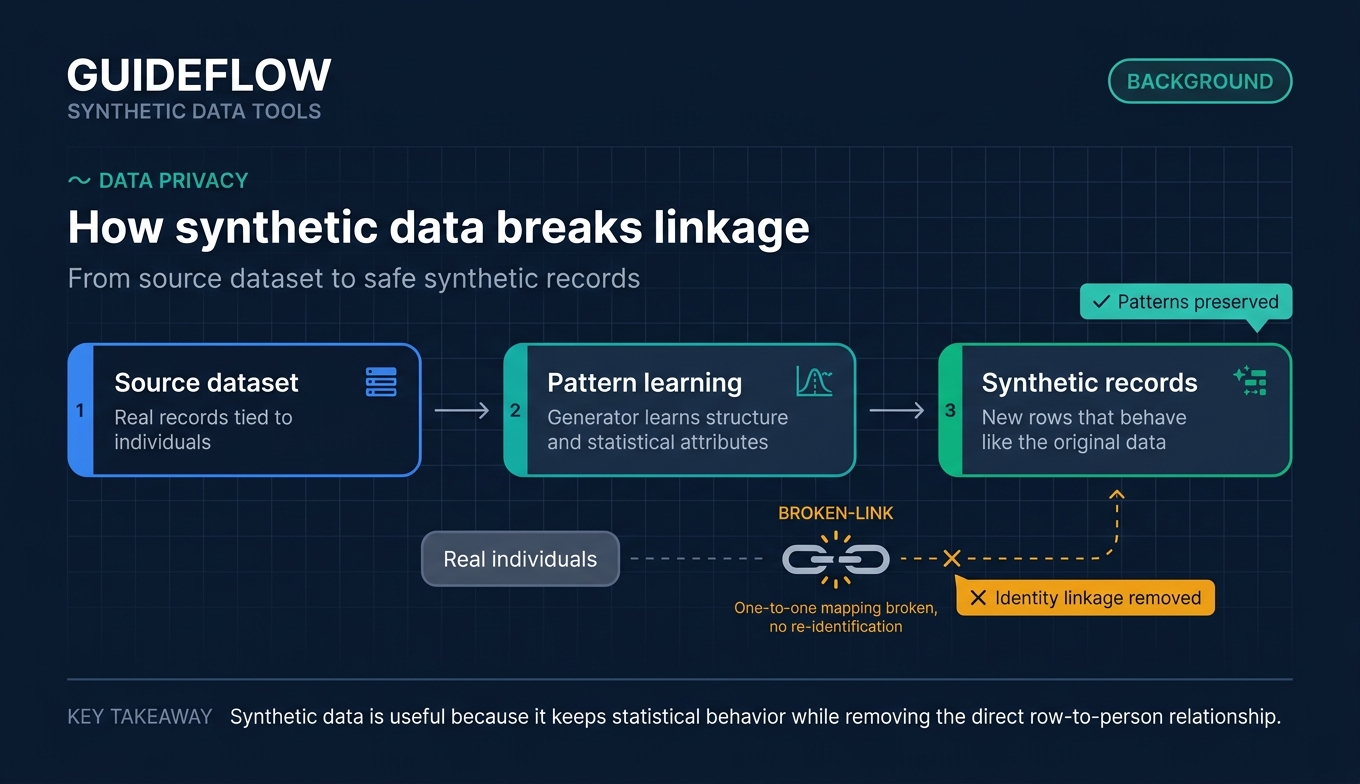
A modern synthetic data platform usually combines several generation methods:
- AI and generative methods: models learn distributions and correlations, then sample new rows that match. Strongest for fidelity on complex, high-dimensional data.
- Rules-based generation: formulas, patterns, and constraints define values directly. Predictable and fast for known schemas.
- Data cloning and subsetting: pull a representative slice of a system while keeping it coherent.
- Masking and de-identification: detect and replace sensitive entities like names, emails, and PHI.
Beyond generation, the capabilities that separate a serious synthetic data platform from a toy generator are:
- Referential integrity: relationships across related tables and systems stay consistent, so a customer ID in one table still resolves correctly in another.
- Quality validation: fidelity, utility, and privacy metrics that tell you whether the output is good enough to use.
- Compliance support: features that help teams align with GDPR, CCPA, and HIPAA by avoiding direct exposure of PII and PHI.
- Integration and automation: APIs, SDKs, and CI/CD hooks so generation runs as part of a pipeline, not a one-off export.
Vendors like K2view describe their platforms as combining AI-powered generation, intelligent masking, rules-based generation, and data cloning, all aimed at producing privacy-compliant test data. G2 defines the category as tools that generate artificial datasets to replicate real-world scenarios for testing and analysis. Both framings point to the same core job: realistic data you can use freely, without the risk of the real thing.
When to use synthetic data tools
Synthetic data earns its place in three recurring situations. Each maps to a different intent and a different subset of the tools below.
Generate realistic test data for software and QA
Production copies in lower environments are a liability. They carry real PII, they go stale, and provisioning them pulls engineering off roadmap work. Synthetic test data generation replaces those copies with realistic, privacy-safe datasets you can regenerate on demand.
This supports the full SDLC: functional testing, negative and edge-case testing, and performance or load testing where you need volume that production cannot safely provide. Tools like K2view, GenRocket, Tonic, and Mockaroo lean hardest into test data management and software testing use cases. Realistic test data also powers convincing interactive demo environments where prospects can explore a product without seeing real customer records.
Train and validate AI, ML, and LLM systems
AI synthetic data solves two model problems at once: scarce data and privacy risk. When you do not have enough real examples, or the real examples are too sensitive to use, synthetic data augments your training set, fills in rare edge cases, and lets you train without touching regulated records.
Teams increasingly use it for RAG and LLM pipelines too, generating evaluation sets and redacting sensitive entities from unstructured text. In practice, most organizations combine synthetic and real data rather than fully replacing one with the other. Synthetic data also fits naturally when you need to populate a safe evaluation or exploration environment, the same reason teams use a Sandbox to let stakeholders explore a product on realistic, non-production data. These same evaluation environments increasingly pair with AI-powered features to speed up creation and personalization.
Protect privacy and meet compliance requirements
When the goal is sharing data across teams, vendors, or borders, synthetic data lets you move datasets that look and behave like production without carrying the underlying personal records. That supports GDPR, CCPA, and HIPAA workflows through PII and PHI de-identification. For teams that need to share demos and data externally with audit-friendly controls, Guideflow's security and compliance posture offers a useful reference point.
Properly generated synthetic data that cannot be linked back to individuals may, in some cases, fall outside the scope of personal data laws. That depends heavily on generation method and re-identification risk, so treat it as a method-dependent benefit, not a guarantee.
Comparison table
The table below summarizes the 15 synthetic data generation tools in this guide, sorted by relevance to AI and testing buyers. Pricing reflects vendor pricing pages and G2 at the time of writing; several enterprise tools publish plan names but quote pricing on request. Where a vendor does not publish a public price, that is noted directly.
| # | Product | Intent | Key use case | Pricing | G2 rating |
|---|---|---|---|---|---|
| 1 | Tonic.ai | High-fidelity test + AI data | Synthetic and de-identified data for dev, QA, and model training | Free; Fabricate Plus from $29/mo; custom enterprise | 4.2/5 |
| 2 | MOSTLY AI | Privacy-safe tabular data | Synthetic tabular data for analytics and ML | Free; Marketplace $3,000/mo; custom enterprise | 4.5/5 |
| 3 | Gretel | Developer-first generation | API and SDK-driven synthetic data for AI/ML | Free account available; pricing on request | 4.4/5 |
| 4 | K2view | Enterprise test data | Multi-method generation with referential integrity | 30-day free trial; pricing on request | 4.6/5 |
| 5 | YData | Data-centric AI | Synthetic data plus data profiling | Free credit; pay-as-you-go $1.00/credit; enterprise | 4.6/5 |
| 6 | Synthetic Data Vault (SDV) | Open-source generation | Code-based tabular synthetic data | Open source; enterprise on request | Not listed |
| 7 | Hazy (SAS Data Maker) | Enterprise synthetic data | Privacy-preserving data for regulated industries | Pricing on request | Not listed |
| 8 | Syntho | Validated synthetic data | AI generation with quality and privacy reports | Quote-based (Basic, Standard, Ultimate) | 4.6/5 |
| 9 | MDClone | Healthcare data | Self-service clinical data exploration | Pricing on request | 4.9/5 |
| 10 | Synthea | Open-source healthcare | Synthetic patient records for research and testing | Free, open source | Not listed |
| 11 | Faker | Developer fake data | Format-correct placeholder data | Free, MIT license | Not listed |
| 12 | GenRocket | Synthetic test data at scale | Rules-based test data for QA and CI/CD | Per-project annual licensing; quote-based | 4.6/5 |
| 13 | Aindo | Privacy-preserving data | Synthetic relational data for regulated sectors | Subscription; pricing on request | Not listed |
| 14 | Tonic Textual | Unstructured data for AI | Redaction and synthesis for LLM and RAG | Pay-as-you-go; custom enterprise | 4.2/5 |
| 15 | Mockaroo | Quick test datasets | Schema-based test data and mock APIs | Free; Silver $60/yr; Gold $500/yr; Enterprise $7,500/yr | 4.2/5 |
Best synthetic data tools for AI and testing in 2026
1. Tonic.ai
Tonic.ai is a synthetic data platform for generating, de-identifying, and subsetting structured and unstructured data for software development, testing, and AI model training. It spans three products: Fabricate for generating data from scratch, Structural for sanitizing production data into high-fidelity test data, and Textual for handling sensitive unstructured text. That breadth is why it sits at the top of this list for teams that need both test data and AI training data from one vendor.
Best for: Engineering and AI teams that need safe, realistic synthetic or de-identified data for development, QA, and model training without exposing production data.
Key strengths
- Generate from scratch: Build fully relational synthetic databases, realistic unstructured data, and mock APIs.
- Sanitize production safely: Produce high-fidelity test data that mirrors production complexity for dev and QA.
- Protect unstructured data: Detect, redact, and synthesize sensitive entities for AI and compliance workflows.
Why choose Tonic.ai
Tonic.ai fits teams that have outgrown one-off scripts and need a single platform covering structured test data, relational generation, and unstructured redaction. The three-product split means you adopt only what you need now and expand later, rather than buying a monolith up front. For regulated industries, the de-identification and compliance posture is the main draw.
Tonic.ai pricing
Tonic publishes pricing per product. Fabricate has a Free plan at $0 per month, a Plus plan at $29 per month, and a custom-priced Enterprise plan. Structural is available in Professional and Enterprise tiers with custom pricing. Textual uses usage-based, pay-as-you-go pricing per 1,000 words processed, plus a custom Enterprise option.
2. MOSTLY AI
MOSTLY AI is a data intelligence platform for securely accessing production data, generating privacy-safe synthetic data, and analyzing and sharing data across teams. Its strength is tabular synthetic data that holds statistical accuracy while protecting privacy, which makes it a clean fit for analytics and ML on sensitive datasets.
Best for: Data teams that need privacy-safe synthetic data, secure data access, and AI-assisted analysis for regulated or sensitive datasets.
Key strengths
- AI assistant: Run natural-language data analysis and Python execution against your data.
- Privacy-safe generation: Produce synthetic data for collaboration, model training, and sharing.
- Mock and simulated data: Build datasets for testing, prototyping, edge cases, and what-if scenarios.
Why choose MOSTLY AI
Choose MOSTLY AI when your primary need is tabular data and your buyers include non-engineers. The platform leans into accessible workflows, so analysts can generate privacy-safe datasets without writing pipeline code. The AI assistant adds an analysis layer on top of generation, which is useful when the same team both creates and queries the data.
MOSTLY AI pricing
MOSTLY AI offers a Free plan with 2 credits per day, capped at 25 credits per month. The Marketplace plan is $3,000 per month for AWS Marketplace deployment with unlimited usage. Enterprise is custom-priced for deployment inside the customer's environment.
3. Gretel
Gretel is a synthetic data platform for creating privacy-safe datasets for AI, ML, analytics, and data sharing. It is built developer-first, so generation runs through APIs and SDKs rather than a click-through UI. If you want an API key synthetic data generator that drops into existing pipelines, this is the natural pick.
Best for: Teams that need privacy-preserving synthetic data for AI/ML model development, evaluation, testing, or regulated data sharing.
Key strengths
- Safe Synthetics: Generate private synthetic versions of sensitive data programmatically.
- Gretel Transform: Detect, redact, replace, or anonymize PII inline.
- Data Designer: Build repeatable pipelines with previews, evaluations, constraints, and scalable generation.
Why choose Gretel
Gretel suits engineering teams that treat synthetic data as part of CI/CD, not a manual export. The SDK and pipeline tooling make generation repeatable and version-controllable, which matters when datasets feed model training or evaluation on a schedule. Pick it when programmatic control outweighs a polished no-code interface.
Gretel pricing
Gretel offers a free account to get started. Detailed plan pricing is not published on its pricing page and is available on request, so confirm current tiers with the vendor before committing.
4. K2view
K2view provides a data product platform for delivering AI-ready, governed, real-time enterprise data products using Micro-Database technology. For synthetic data, it combines AI-powered generation, intelligent masking, rules-based generation, and data cloning, with referential integrity maintained across systems. That cross-system integrity is its defining strength.
Best for: Large enterprises needing governed, real-time, entity-based data for complex relational test data, AI, and CI/CD.
Key strengths
- Multi-method generation: Combine AI, rules, cloning, and masking in one platform.
- Micro-Database technology: Organize each business entity into its own encrypted data store.
- AI-automated engineering: Automate discovery, classification, and pipeline generation.
Why choose K2view
K2view is built for the hardest version of the test data problem: many related systems that must stay consistent. When a customer record spans a dozen tables and services, K2view keeps the synthetic version coherent end to end. That makes it a fit for enterprise QA and CI/CD where broken referential integrity would invalidate every test.
K2view pricing
K2view does not publish public pricing. It offers a 30-day free trial at no charge, and plan pricing is available through the vendor. Confirm current terms directly before purchase.
5. YData
YData provides synthetic data and data profiling tools to help data teams build better datasets for AI. The combination matters: it pairs synthetic data generation with automated profiling, so you can improve the underlying data quality, not just generate more of it.
Best for: Data science and AI teams that need synthetic data generation, profiling, and privacy-preserving datasets.
Key strengths
- Synthetic data generation: Create privacy-preserving datasets for modeling.
- Automated profiling: Surface data quality issues before they reach your models.
- Synthetic database generation: Produce structured datasets, not just single tables.
Why choose YData
YData fits data-centric teams that believe model performance is a data problem first. The profiling layer helps you find gaps, bias, and quality issues, then generate synthetic data to address them. Choose it when improving dataset quality is as important as producing volume.
YData pricing
YData SDK offers a Free plan with a free monthly credit, a Pay-as-you-go plan at $1.00 per credit, where one credit covers 1 million data points or 10,000 tokens, and an Enterprise plan with predictable pricing available on request.
6. Synthetic Data Vault (SDV)
Synthetic Data Vault (SDV) is a Python library and ecosystem for generating and evaluating synthetic tabular data across single-table, multi-table, and sequential datasets. As an open-source synthetic data platform, it is free to use and fully programmatic, which makes it the default starting point for developers and researchers who want code-based generation.
Best for: Data science and engineering teams that need programmatic, on-prem synthetic tabular data generation and evaluation.
Key strengths
- Train generative models: Handle single-table, sequential, and multi-table relational data.
- Evaluate quality: Compare synthetic data against real data with built-in visualization.
- Customize synthesizers: Apply constraints, preprocessing, and anonymization options.
Why choose SDV
SDV is the right call when you want full control, no licensing cost, and the ability to run everything on your own infrastructure. It is code-first, so it suits teams comfortable in Python who want to validate fit before paying for a commercial platform. The built-in evaluation tools also make it useful purely for benchmarking synthetic data quality.
SDV pricing
The open-source SDV library is free to use. An SDV Enterprise offering is available to licensed users, with pricing arranged directly with the team rather than published publicly.
7. Hazy (SAS Data Maker)
Hazy was a synthetic data technology whose principal software assets were acquired by SAS and integrated into SAS Data Maker for enterprise synthetic data generation. If you evaluated Hazy previously, this is where that capability now lives, inside SAS's enterprise data tooling.
Best for: Enterprises needing privacy-preserving synthetic data for AI, analytics, testing, and regulated-data collaboration.
Key strengths
- Low-code generation: Produce synthetic data that mirrors real-world datasets without heavy coding.
- Data augmentation: Generate and augment data using SAS algorithms.
- Automated evaluation: Get visual statistical metrics for data quality and privacy.
Why choose Hazy (SAS Data Maker)
This fits organizations already invested in, or evaluating, the SAS ecosystem and needing synthetic data for regulated, privacy-sensitive use cases. The automated evaluation metrics matter for teams that must document data quality and privacy for sign-off. Note the lineage: the standalone Hazy product now ships as part of SAS Data Maker.
Hazy (SAS Data Maker) pricing
SAS Data Maker does not display public pricing, plan tiers, or a Hazy-specific free tier. Pricing is handled through SAS's contact and get-started flows, so confirm terms directly with the vendor.
8. Syntho

Syntho is an all-in-one platform for generating privacy-safe synthetic data that mirrors original data without compromising sensitive information. Its standout is built-in quality assurance reporting, which gives compliance and data teams the evidence they need to approve a dataset for use.
Best for: Organizations that need privacy-safe synthetic test or analytics data from structured databases while preserving utility and referential integrity.
Key strengths
- AI-powered masking: Scan for PII, generate synthetic mock data, and keep consistent mapping.
- Rule-based generation: Use formulas, patterns, and subsetting for controlled output.
- Quality assurance reporting: Get AI-generated data with QA reports, time-series synthesis, and upsampling.
Why choose Syntho
Syntho fits teams where a compliance owner has to sign off before data moves. The quality and privacy assurance reports turn "trust us" into documented evidence, which shortens approval cycles. It is a strong pick when validation reporting is a hard requirement, not a nice-to-have.
Syntho pricing
Syntho uses feature-based licensing with no consumption-based charges. Plans are Basic, Standard, and Ultimate, each priced by quote rather than a published number, so contact the vendor for current figures.
9. MDClone
MDClone provides the ADAMS Platform, a self-service healthcare data exploration environment for secure analysis, collaboration, research, and innovation using structured, unstructured, and synthetic healthcare data. It is purpose-built for clinical settings where patient privacy is non-negotiable.
Best for: Healthcare systems and life sciences organizations that need secure, self-service exploration of clinical data and synthetic-data-enabled collaboration.
Key strengths
- Self-service exploration: Let healthcare teams explore multi-source data without programming skills.
- Synthetic collaboration: Share data securely across teams, organizations, and third parties.
- Broad data support: Handle structured and unstructured patient data, cohorts, and visualization.
Why choose MDClone
MDClone fits healthcare and research teams that need to move clinical data between collaborators without exposing real patient records. The self-service model reduces dependency on data engineering for every cohort request. It is the specialist choice when the data is clinical and the stakes are patient privacy.
MDClone pricing
MDClone does not publish public pricing. The platform is offered through a demo and request flow rather than a self-serve plan, so engage the vendor directly for pricing.
10. Synthea
Synthea is an open-source synthetic patient generator that models synthetic patients' medical histories for Health IT research, development, and policy simulation. It is free, unrestricted, and widely used as the default open-source option for healthcare data.
Best for: Health IT teams, researchers, and policy analysts needing realistic synthetic patient records without using real patient data.
Key strengths
- Full medical histories: Generate medications, allergies, encounters, and social determinants of health.
- Generic Module Framework: Model disease progression, treatment, and clinical events.
- Standard exports: Output data in HL7 FHIR, C-CDA, and CSV formats.
Why choose Synthea
Synthea is the free starting point for any healthcare data need. Because output carries no cost, privacy, or security restrictions, you can share it openly and integrate it into Health IT systems without procurement. Choose it when you want clinical realism without a vendor relationship.
Synthea pricing
Synthea is open source and free to use, with no cost and no restrictions on the resulting data. There is no paid tier or licensing fee.
11. Faker
Faker is a JavaScript library for generating fake but realistic data for testing and development. One clarification matters: Faker generates format-correct fake data, like names and addresses, but it does not reproduce the statistical properties of a real source dataset. That makes it a fast data generator for placeholder data, not a statistically faithful synthetic data generator.
Best for: Developers who need realistic test, demo, seed, or mock data in JavaScript projects.
Key strengths
- Broad data types: Generate person, location, date, finance, commerce, and localized data.
- Runs anywhere: Use it in the browser and in Node.js.
- Modular API: Pull from basic datatypes, topic-specific modules, and helper utilities.
Why choose Faker
Faker is the quickest way to fill a database, UI, or test with believable placeholder data. It is ideal early in development when you need volume and format, not statistical fidelity. Just do not mistake it for a model-based tool: if your tests depend on real distributions, pair it with one of the synthetic data platforms above.
Faker pricing
Faker is open source and free under the MIT license, available for commercial and non-commercial use. There are no paid plans.
12. GenRocket
GenRocket is a synthetic test data automation platform for designing and generating secure, on-demand test data for quality engineering and related use cases. With 750+ data generators and broad format support, it is built for QA and DevOps teams that need test data at scale.
Best for: Enterprise QA, DevOps, and data teams that need secure synthetic test data generated on demand across complex systems and CI/CD pipelines.
Key strengths
- Massive generator library: Use 750+ data generators and 110+ data formats.
- Data protection built in: Apply masking, subsetting, and PII detection.
- Self-service portal: Generate data through a portal with CI/CD pipeline integration.
Why choose GenRocket
GenRocket fits QA organizations that treat test data as a managed, automated capability rather than a manual chore. The self-service portal and CI/CD integration let testers provision exactly the data a scenario needs, on demand. It is a strong synthetic test data generation choice for teams running continuous testing at enterprise scale.
GenRocket pricing
GenRocket uses test-data-project-based pricing, billed as an annual per-project license with a minimum of 20 projects. The annual license total, single-tenant hosting, accelerators, and project add-ons are quoted rather than published, so request a quote for current figures.
13. Aindo
Aindo provides a synthetic data platform for generating privacy-preserving, statistically representative datasets for healthcare, life sciences, finance, and public-sector use cases. It pairs generation with utility and privacy evaluation, so you can measure both sides of the tradeoff.
Best for: Organizations needing compliant synthetic health, research, financial, or public-sector datasets without exposing sensitive personal data.
Key strengths
- Relational generation: Produce synthetic data for relational and tabular datasets.
- Privacy-preserving sharing: Share data with utility and privacy evaluation metrics.
- Data utilities: Use data completion, compatibilization, bias removal, and dashboards.
Why choose Aindo
Aindo suits regulated sectors where datasets are relational and privacy scrutiny is high. The evaluation metrics give data and compliance teams a quantified view of how useful and how private a synthetic dataset is. Choose it when you operate in healthcare, finance, or public-sector contexts that demand both fidelity and defensible privacy.
Aindo pricing
Aindo describes a subscription model with two main levels, an experimental subscription and a commercial Enterprise subscription, with a minimum duration. Public price figures are not published, so contact the vendor for current terms.
14. Tonic Textual
Tonic Textual is an unstructured data redaction and synthesis solution for detecting and protecting sensitive text and audio data for AI workflows. While it shares the Tonic platform, it earns its own entry because unstructured data is a distinct, growing problem for LLM and RAG pipelines.
Best for: Teams that need to safely redact or synthesize sensitive unstructured data for AI training, RAG, LLM workflows, analytics, or compliance-sensitive sharing.
Key strengths
- Entity detection: Find sensitive entities in unstructured text with proprietary NER models.
- Redact or synthesize: Protect sensitive entities while preserving context and usability.
- Developer access: Run Textual pipelines through a Python SDK and REST API.
Why choose Tonic Textual
Tonic Textual fits AI teams building on documents, transcripts, and other free text where PII hides in prose, not columns. It preserves enough context that redacted data stays useful for training and retrieval, which generic masking often breaks. Pick it when your AI data is unstructured and compliance is in scope.
Tonic Textual pricing
Tonic Textual uses volume-based pricing by number of words processed. The pricing page lists a Pay-as-you-go plan and a custom-priced Enterprise plan, without a public numeric rate, so confirm current usage rates with Tonic.
15. Mockaroo
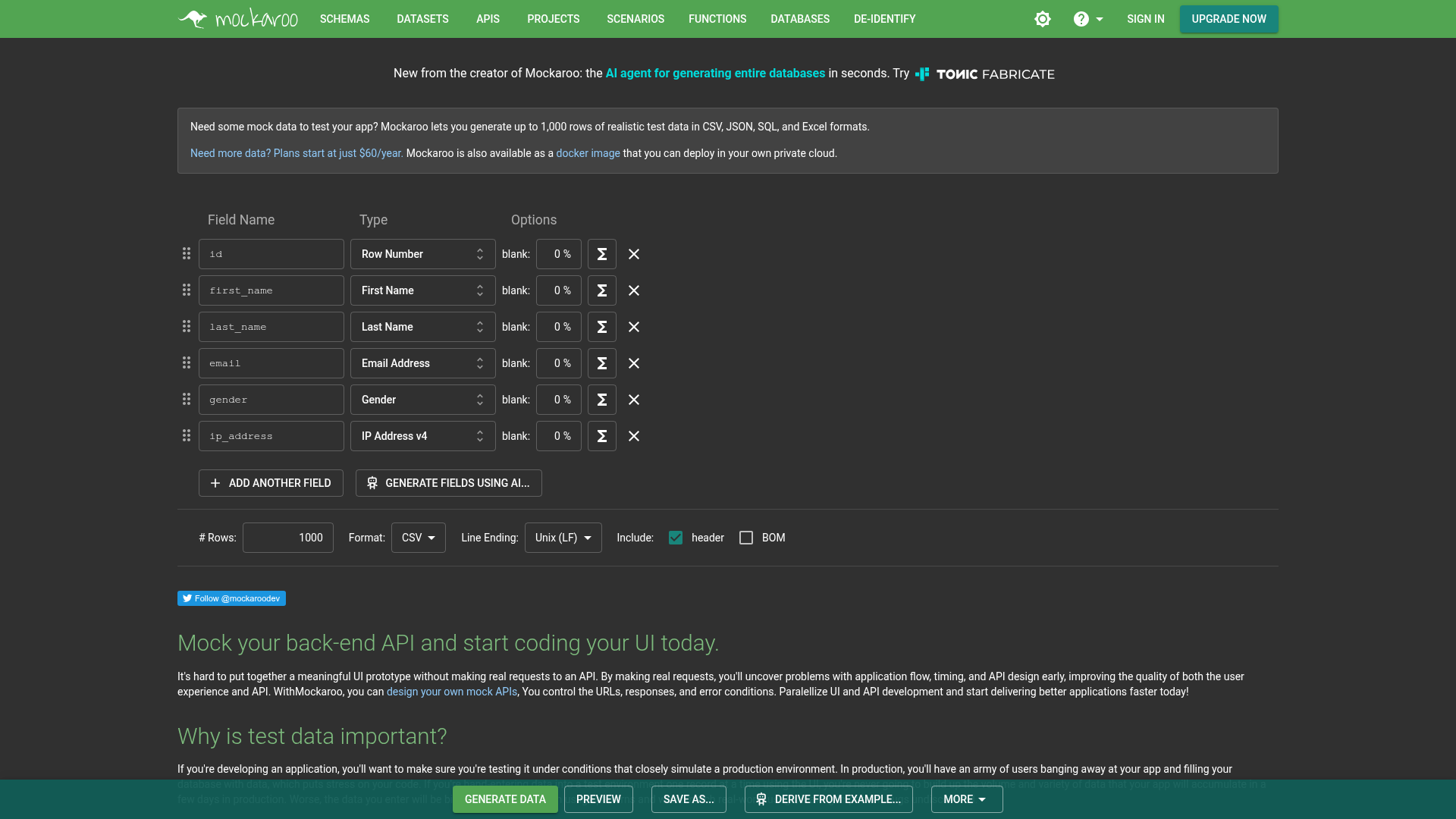
Mockaroo is a random test data generator and API mocking tool for creating realistic CSV, JSON, SQL, and Excel datasets. It is the lightest-weight option here: a browser-based data generator that gets a usable dataset out the door in minutes.
Best for: Developers and QA teams that need realistic test datasets and mock APIs for software testing, demos, and UI development.
Key strengths
- Multi-format export: Generate realistic data in CSV, JSON, SQL, and Excel.
- Mock APIs: Design mock endpoints with custom responses, error conditions, and variables.
- Flexible data types: Use 100+ built-in types, reference data uploads, or a formula API.
Why choose Mockaroo
Mockaroo is the fast, schema-based option for PMs and developers who need a custom test dataset right now. You define fields in the browser, pick formats, and export, with no pipeline to build. Choose it for quick, ad-hoc datasets and API mocking rather than statistically faithful, large-scale generation.
Mockaroo pricing
Mockaroo's Free plan covers 1,000 rows per file and 200 API requests per day. Silver is $60 per year for up to 100,000 rows per file and 1 million records per day via API. Gold is $500 per year for up to 10 million rows per file, and Enterprise is $7,500 per year for unlimited data, users, and API calls, with private hosting options.
Considerations: how to choose a synthetic data tool
The right tool depends on your data, your constraints, and who has to use it. Run any shortlist through these five criteria before you commit.
Data realism and referential integrity
Ask whether generated data preserves relationships across tables and systems, not just the distribution within a single column. If a customer ID has to resolve correctly across orders, payments, and support tickets, you need a tool built for referential integrity, like K2view. Single-table fidelity is not enough for relational testing.
Privacy and compliance
Check how the tool handles PII and PHI, and what it gives you to prove compliance. Masking and de-identification features matter, but so do validation and audit reports that document privacy for GDPR, HIPAA, or CCPA sign-off. Tools like Syntho and Aindo lead with explicit privacy evaluation.
Workflow integration and automation
Decide whether you need a no-code interface, an API, or both. Developer-first tools like Gretel and SDV fit CI/CD and pipeline generation, while platforms like MOSTLY AI serve non-technical analysts. The best fit is the one that lives where your team already works. If you also need to surface that data inside customer-facing demos, look for tools with strong integrations into your existing stack.
Maintenance and scalability
For PMs especially, low maintenance is the hidden cost that decides long-term fit. Ask how the tool holds up as schemas change and products ship, and whether generation can run without pulling engineering into every request. A tool that breaks on every release is a recurring tax, not a solution.
Cost and licensing
Map the pricing model to your usage. Open-source options like SDV, Synthea, and Faker cost nothing to start, while enterprise platforms use seat-based, usage-based, or custom annual licensing. Verify current pricing directly with each vendor, since several quote rather than publish.
Conclusion
The synthetic data tools market is broad enough that the right answer depends entirely on the job. For high-fidelity test data plus AI training data from one vendor, Tonic.ai is the strongest all-rounder. For privacy-safe tabular data with a no-code interface, MOSTLY AI fits. Developer teams that live in APIs should evaluate Gretel, and enterprises with complex relational systems will want K2view for its referential integrity.
If your work is healthcare-specific, MDClone and Synthea cover clinical needs, with Synthea offering a free open-source path. For unstructured AI data, Tonic Textual handles the redaction and synthesis that column-based tools miss. And when you just need a quick, custom test dataset, Mockaroo gets you there in minutes.
A sensible next step: start with a free or open-source option like SDV, Synthea, or Mockaroo to validate that synthetic data solves your specific problem. Once you have proof of fit, trial an enterprise platform that matches your scale, compliance, and integration requirements. If your end goal is showcasing that data in a buyer-ready experience, explore the best AI sales tools and best product analytics software to round out your stack. Verify pricing and current capabilities directly with each vendor before you buy.
FAQ
Anonymization masks or alters real records in place, which leaves a residual link back to actual people and some re-identification risk. Synthetic data is newly generated to mirror the statistical patterns of a source dataset without a one-to-one mapping to real individuals. That makes well-built synthetic data lower-risk for sharing and testing.
Properly generated synthetic data that cannot be linked back to individuals may, in some cases, fall outside the scope of personal data laws. Whether it does depends heavily on the generation method and the re-identification risk of the output. Compliance is not automatic, so validate it per tool and per use case rather than assuming it.
Synthetic data is valuable for augmenting scarce datasets, covering edge cases, and enabling privacy-safe training. In practice, fidelity and validation determine how far it can go, and most teams use synthetic data alongside real data rather than fully replacing it. The right mix depends on your model and how well the synthetic data preserves the patterns that matter.
For open-source generation, Synthetic Data Vault (SDV) is the leading Python library for tabular data. Synthea is the standard for free synthetic patient records in healthcare, and Faker generates free, format-correct fake data for development and testing. All three are free to start, though Faker produces placeholder data rather than statistically faithful synthetic data.
Quality is usually measured across three dimensions: fidelity, meaning statistical similarity to the real data; utility, meaning how well models or tests perform on it; and privacy, meaning re-identification risk. Referential integrity is a fourth check for relational data, confirming that relationships across tables stay consistent. Tools like SDV and Syntho include built-in evaluation for these metrics.
For test data management and software testing, K2view, GenRocket, Tonic, and Mockaroo are the most focused options in this guide. K2view and GenRocket handle enterprise-scale, CI/CD-integrated generation, Tonic covers high-fidelity test data and de-identification, and Mockaroo is the quickest path to a custom, schema-based dataset. Pick based on scale and how much automation you need.
Pricing spans free open-source libraries to enterprise platforms with custom contracts. Some tools publish public prices, like Mockaroo from $60 per year or Tonic Fabricate Plus at $29 per month, while many enterprise vendors use seat-based, usage-based, or quote-based annual licensing. Always confirm current pricing directly with the vendor, since several do not publish figures.
Referential integrity means the relationships between related tables and systems stay consistent in the generated data. For example, a customer ID created in one table still resolves correctly in linked tables for orders, payments, and support. Without it, synthetic datasets fail relational tests, which is why enterprise tools like K2view treat cross-system integrity as a core capability.




.avif)





